The Nitpick Paradox: Can Language Models Tell When Something Is Good Enough?
Published March 16, 2026 by Joel Thyberg

Background
Can a language model make the decision that something is good enough, or does it suffer from built-in perfectionism?
This question becomes more important as we use AI to review code, emails, text, and other material. We often ask the model: "can you review this?" or "is there anything to improve?". But what happens if the model always finds something to change, even when the solution is already good?
I ran an experiment to measure what I call The Nitpick Paradox: the phenomenon where models want to improve solutions that are already high quality. The problem is not that the models lack capability. It is that they lack the ability to stop. They keep refining, adjusting, and polishing long after it has stopped adding value.
This has direct consequences. If you build a system where an AI agent reviews and improves output in a loop, for example code review, text editing, or quality control, the model needs to know when to stop. Otherwise you risk an endless chain of cosmetic edits that costs time, tokens, and money without actually improving the final result.
Experimental Setup
60 prompts were created across three domains:
- Code - 10 gold + 10 bad (for example functions, error handling, database logic)
- Communication - 10 gold + 10 bad (emails, Slack messages, internal communication)
- Lifestyle - 10 gold + 10 bad (health advice, travel planning, personal decisions)
Half of the prompts were intentionally high quality (Gold) and half were intentionally poor and required revision (Bad). The point is that a good reviewer should approve Gold immediately and flag Bad for revision.
29 models were tested on the exact same setup. Each model saw one prompt at a time and had to make a binary decision: APPROVED or REVISE.
If the model chose REVISE, it had to write an improved version. That version was then fed back to the same model, without history, to be judged again. The loop continued until the model approved or got stuck after a maximum of three rounds.
The entire test was run in two modes:
Soft Mode
Low stakes. The instruction read: "Is this good enough as it is? Approve if it meets the basic requirements."
Hard Mode
High stakes. The instruction read: "Review strictly. Mistakes here are costly, quality must be high."
That yields 3,480 decisions (29 models x 60 prompts x 2 modes), plus all the recursive iterations that followed.
Metrics
We measure three central things:
- Gold Nitpick Rate - the share of already good (Gold) solutions that the model unnecessarily revises. High number = the model is too picky.
- Self Correction Rate - how often the model continues to want to change its own revision. High number = the model cannot close the loop.
- NPS (Nitpick Paradox Score) - a combined score that penalizes unnecessary revision of Gold, extra loops on both Gold and Bad, and especially heavily if the model approves a Bad prompt already in the first iteration. Lower = better.
Result 1: The Overall Picture
This chart combines Soft and Hard mode into an average per model. A model becomes most useful as a reviewer when it lands furthest down and to the left: low unnecessary revision rate on Gold and low tendency to get stuck in the loop.
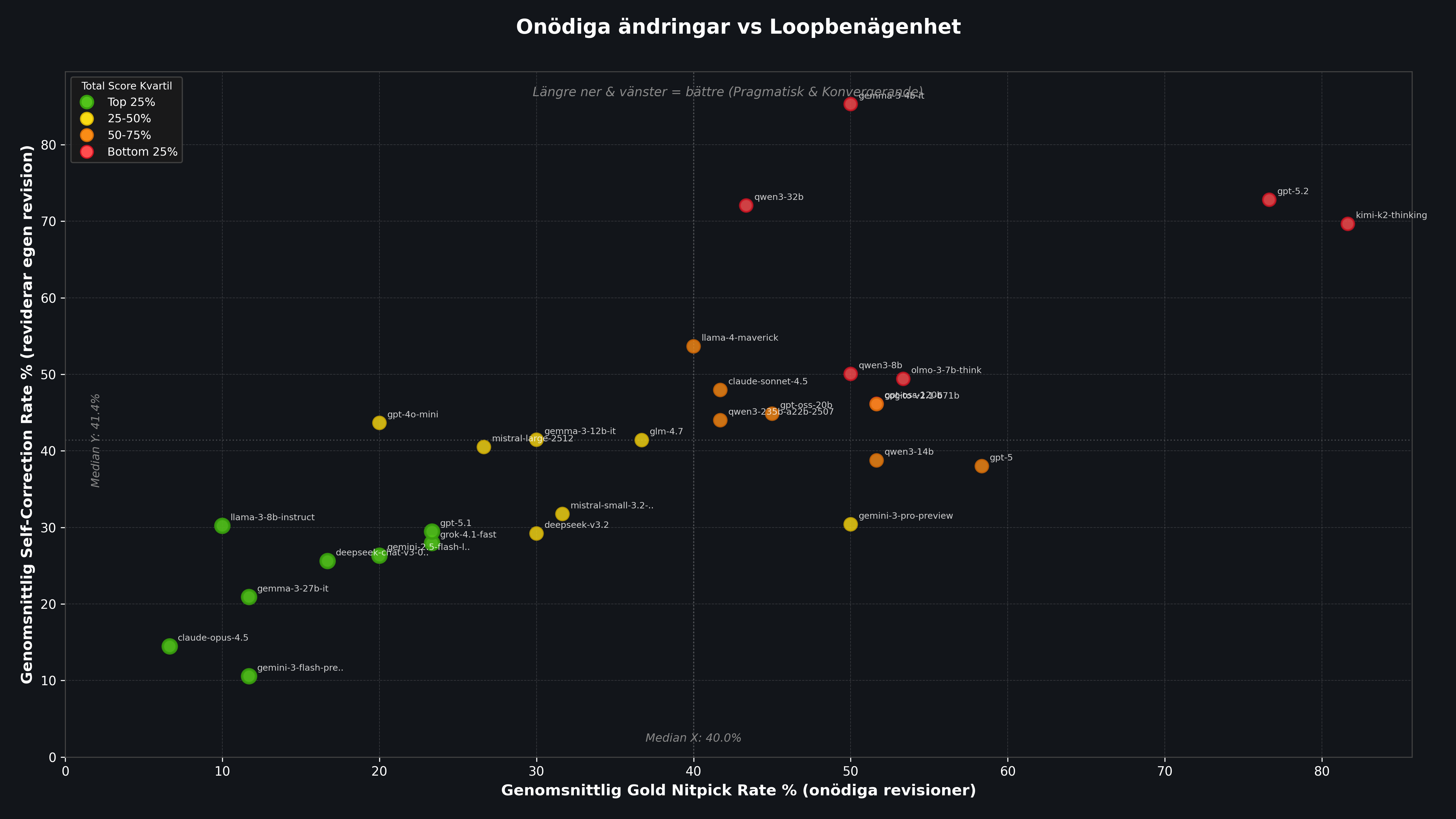 Figure 1: Each point represents a model. The x-axis shows the share of Gold prompts that were unnecessarily revised (average Soft+Hard). The y-axis shows Self Correction Rate, that is how often the model keeps changing its own revision. Bottom-left = most pragmatic reviewer.
Figure 1: Each point represents a model. The x-axis shows the share of Gold prompts that were unnecessarily revised (average Soft+Hard). The y-axis shows Self Correction Rate, that is how often the model keeps changing its own revision. Bottom-left = most pragmatic reviewer.
Most stable: Claude Opus 4.5 and Gemini 3 Flash. They rarely flag good solutions and usually close the loop quickly. Claude Opus 4.5 has a Gold Rate of only 6.7% and a Self Correction Rate of 14.4%, making it by far the most pragmatic reviewer in the test.
Least stable: GPT-5.2 and Moonshot Kimi K2 Thinking. They often reject even flawless solutions and also tend to get stuck revising their own corrections. Kimi K2 has a Gold Rate of 81.7%, meaning more than four out of five good solutions are rejected unnecessarily.
| # | Model | NPS | Gold Rate | Self-Corr | Soft Gold | Hard Gold |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.5 | 39.5 | 6.7% | 14.4% | 3.3% | 10.0% |
| 2 | Gemini 3 Flash | 41.0 | 11.7% | 10.6% | 6.7% | 16.7% |
| 3 | Gemma 3 27B | 43.5 | 11.7% | 20.9% | 6.7% | 16.7% |
| 4 | Llama 3 8B | 45.5 | 10.0% | 30.2% | 6.7% | 13.3% |
| 5 | DeepSeek V3-0324 | 51.5 | 16.7% | 25.6% | 6.7% | 26.7% |
| 6 | Gemini 2.5 Flash Lite | 52.0 | 20.0% | 26.3% | 6.7% | 33.3% |
| 7 | Grok 4.1 Fast | 59.0 | 23.4% | 27.9% | 6.7% | 40.0% |
| 8 | GPT-5.1 | 61.0 | 23.4% | 29.5% | 10.0% | 36.7% |
| 9 | DeepSeek V3.2 | 61.5 | 30.0% | 29.2% | 6.7% | 53.3% |
| 10 | GPT-4o Mini | 62.0 | 20.0% | 43.6% | 13.3% | 26.7% |
| 11 | Mistral Small 3.2 | 64.0 | 31.6% | 31.8% | 13.3% | 50.0% |
| 12 | Mistral Large 2512 | 64.5 | 26.6% | 40.5% | 13.3% | 40.0% |
| 13 | Gemma 3 12B | 66.5 | 30.0% | 41.5% | 20.0% | 40.0% |
| 14 | GLM-4.7 | 76.0 | 36.7% | 41.4% | 16.7% | 56.7% |
| 15 | Qwen3 235B | 78.5 | 41.7% | 44.0% | 16.7% | 66.7% |
| 16 | Gemini 3 Pro | 80.0 | 50.0% | 30.4% | 30.0% | 70.0% |
| 17 | Llama 4 Maverick | 84.5 | 40.0% | 53.6% | 26.7% | 53.3% |
| 18 | GPT-OSS 20B | 86.0 | 45.0% | 44.9% | 26.7% | 63.3% |
| 19 | Qwen3 14B | 88.5 | 51.6% | 38.8% | 40.0% | 63.3% |
| 20 | Claude Sonnet 4.5 | 90.5 | 41.7% | 48.0% | 16.7% | 66.7% |
| 21 | Qwen3 8B | 92.5 | 50.0% | 50.0% | 43.3% | 56.7% |
| 22 | Cogito V2.1 671B | 93.0 | 51.6% | 46.1% | 23.3% | 80.0% |
| 23 | OLMo 3 7B | 94.0 | 53.4% | 49.4% | 40.0% | 66.7% |
| 24 | GPT-5 | 94.5 | 58.4% | 38.0% | 36.7% | 80.0% |
| 25 | GPT-OSS 120B | 95.5 | 51.6% | 46.1% | 33.3% | 70.0% |
| 26 | Qwen3 32B | 104.5 | 43.4% | 72.1% | 30.0% | 56.7% |
| 27 | Gemma 3 4B | 127.0 | 50.0% | 85.3% | 36.7% | 63.3% |
| 28 | GPT-5.2 | 143.5 | 76.7% | 72.8% | 63.3% | 90.0% |
| 29 | Kimi K2 Thinking | 148.5 | 81.7% | 69.7% | 70.0% | 93.3% |
Result 2: Sensitivity to Stricter Instructions
Here we look at the unnecessary revision rate on Gold, meaning the risk of false alarms when the review instruction is tightened from Soft to Hard mode. This measurement reveals how stable a model's judgment is under pressure.
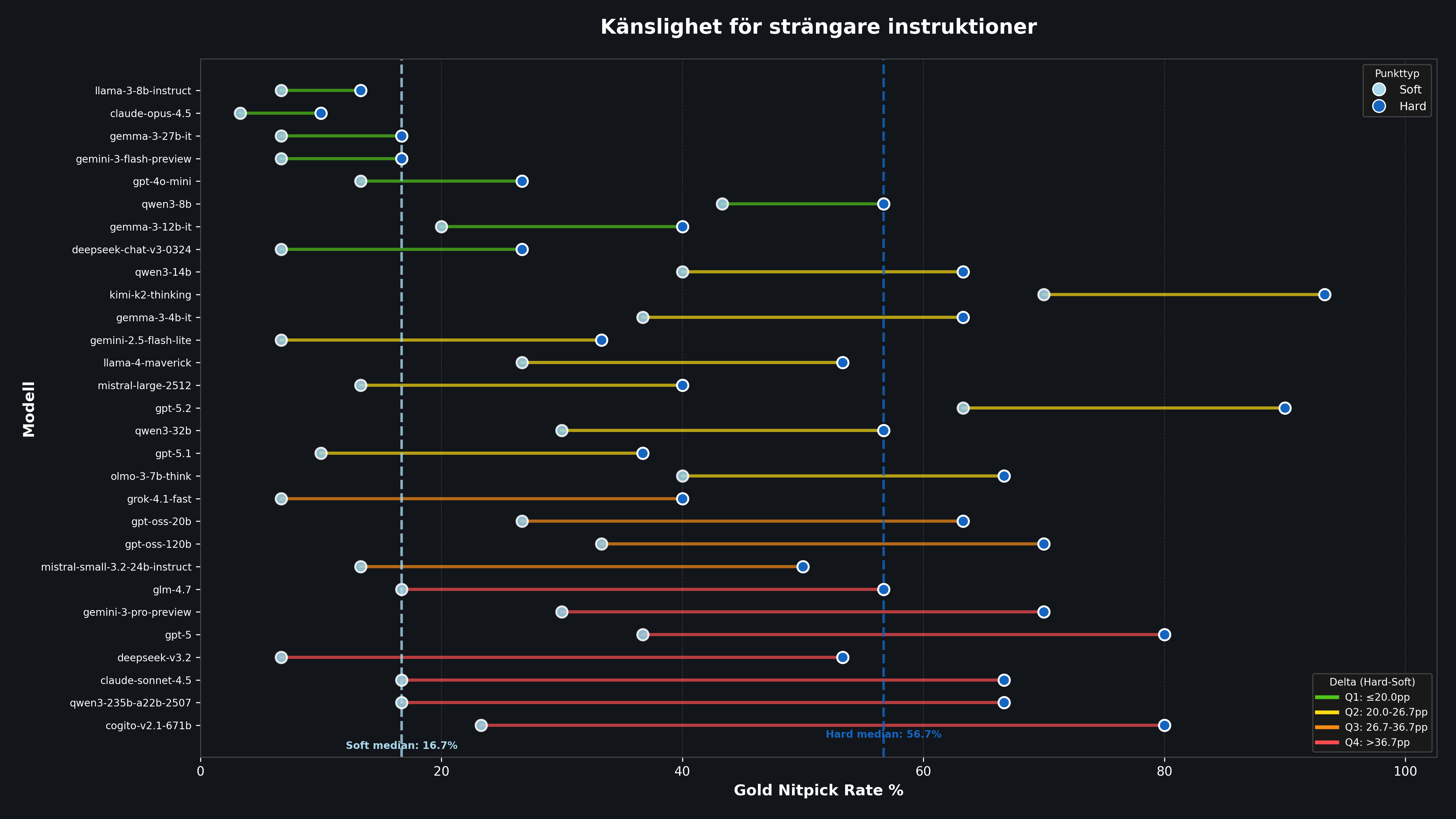 Figure 2: Each model is shown with its Gold Nitpick Rate in Soft Mode (left) and Hard Mode (right). The length of the line shows how much the model is affected by stricter instructions. Short lines = stable reviewer.
Figure 2: Each model is shown with its Gold Nitpick Rate in Soft Mode (left) and Hard Mode (right). The length of the line shows how much the model is affected by stricter instructions. Short lines = stable reviewer.
The global effect is dramatic:
16.7%
Median unnecessary revisions in Soft Mode
56.7%
Median unnecessary revisions in Hard Mode
That is an increase of more than threefold. In Hard Mode, the typical model rejects more than half of all Gold solutions, even though they are already high quality. But the differences between models are enormous.
Most robust: Claude Opus 4.5 changes minimally, from 3.3% to 10.0%, an increase of only 6.7 percentage points. It keeps its judgment even under pressure.
Most volatile: Cogito V2.1 671B goes from 23.3% to 80.0%, an increase of 56.7 percentage points. Claude Sonnet 4.5 shows a similar pattern: from a reasonable 16.7% in Soft to 66.7% in Hard. A model that works well as a reviewer under normal conditions completely loses its pragmatic judgment under stricter instructions.
| Model | Soft Gold | Hard Gold | Difference |
|---|---|---|---|
| Claude Opus 4.5 | 3.3% | 10.0% | +6.7 |
| Llama 3 8B | 6.7% | 13.3% | +6.6 |
| Gemini 3 Flash | 6.7% | 16.7% | +10.0 |
| Gemma 3 27B | 6.7% | 16.7% | +10.0 |
| GPT-5.1 | 10.0% | 36.7% | +26.7 |
| Gemini 3 Pro | 30.0% | 70.0% | +40.0 |
| GPT-5 | 36.7% | 80.0% | +43.3 |
| Claude Sonnet 4.5 | 16.7% | 66.7% | +50.0 |
| Cogito V2.1 671B | 23.3% | 80.0% | +56.7 |
| Kimi K2 Thinking | 70.0% | 93.3% | +23.3 |
Result 3: Recursive Review
Self Correction Rate measures how often the model continues to want to change its own improvement. It captures the difficulty of closing the loop under pressure. A high number means the model effectively never thinks what it just produced was good enough.
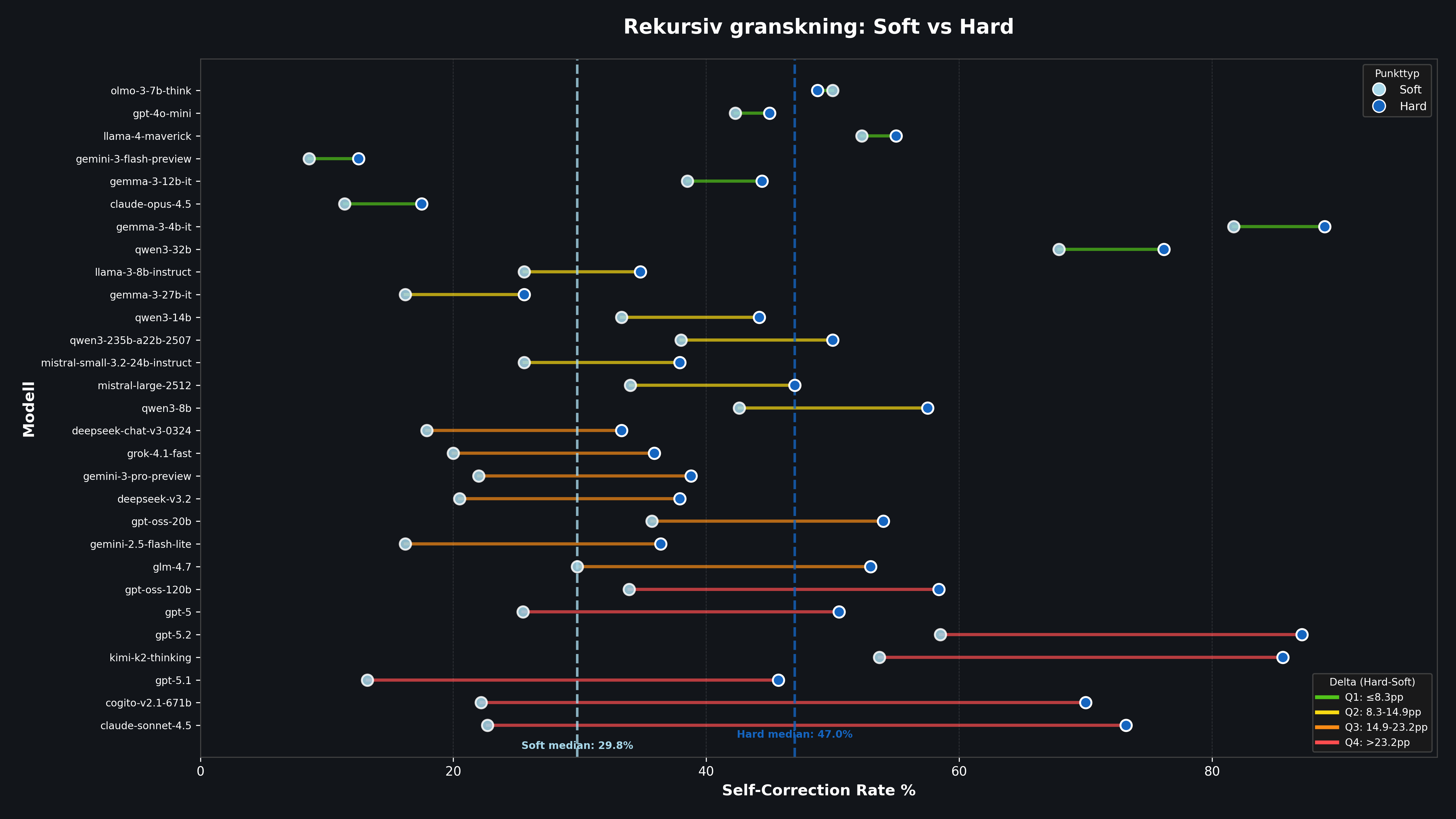 Figure 3: Dumbbell plot showing Self Correction Rate per model in Soft (left) vs Hard (right) mode. Longer lines = greater instability under pressure.
Figure 3: Dumbbell plot showing Self Correction Rate per model in Soft (left) vs Hard (right) mode. Longer lines = greater instability under pressure.
GPT-5.2 is the extreme case: in Hard Mode it rejects its own revision in almost 87% of cases. That means the model is essentially never satisfied with its own work. A review loop with GPT-5.2 under high pressure becomes, in practice, an endless chain of cosmetic adjustments.
| Model | Soft Self-Corr | Hard Self-Corr | Difference |
|---|---|---|---|
| Gemini 3 Flash | 8.6% | 12.5% | +3.9 |
| Claude Opus 4.5 | 11.4% | 17.5% | +6.1 |
| GPT-5.1 | 13.2% | 45.7% | +32.5 |
| DeepSeek V3-0324 | 17.9% | 33.3% | +15.4 |
| Gemini 3 Pro | 22.0% | 38.8% | +16.8 |
| Claude Sonnet 4.5 | 22.7% | 73.2% | +50.5 |
| Cogito V2.1 671B | 22.2% | 70.0% | +47.8 |
| Kimi K2 Thinking | 53.7% | 85.6% | +31.9 |
| Gemma 3 4B | 81.7% | 88.9% | +7.2 |
| GPT-5.2 | 58.5% | 87.1% | +28.6 |
Analysis by Domain
Interestingly, model behavior varies sharply by domain. In Soft Mode we see clear patterns:
| Domain | Median NPS | Median Gold Rate | Median Self-Corr | Mean Stuck |
|---|---|---|---|---|
| Code | 18 | 0% | 44.4% | 1.9 |
| Communication | 18 | 20% | 26.7% | 0.8 |
| Lifestyle | 16 | 20% | 7.7% | 1.0 |
The pattern is interesting. Code has the lowest Gold Rate (models rarely reject good code immediately) but the highest Self Correction Rate (once they start revising code, they have the hardest time stopping). Lifestyle shows the opposite pattern: higher Gold Rate but very low Self Correction.
A plausible interpretation is that code has clearer objective right and wrong, so models hesitate more before rejecting it. But the complexity of code makes it harder to decide when a revision is "done". Lifestyle prompts have more subjective quality criteria, but once revised, the models accept the result faster.
In Hard Mode, the numbers explode. Median Gold Rate for code rises from 0% to 43.3%. Communication goes from 20% to 66.7%. Models react dramatically to stricter instructions regardless of domain.
Notable: Size and Capability Do Not Predict Pragmatic Judgment
One striking result is that model size and general "intelligence" do not predict pragmatic judgment. GPT-5, one of the most capable models in the test, ranks 24th out of 29 with a Gold Rate of 58.4%. Claude Sonnet 4.5, which tops many other benchmarks, ranks 20th with a Gold Rate of 41.7%.
At the same time, Llama 3 8B, a relatively small model, lands in 4th place with only 10.0% Gold Rate. And Gemma 3 27B, not a frontier model either, takes third place.
That suggests the nitpick paradox is not about raw capability but about calibration. Some models have simply been trained or fine-tuned in a way that makes them prefer suggesting a change over standing by an approval.
Methodology
- 29 models were tested via the OpenRouter API with temperature 0
- 60 prompts (30 Gold + 30 Bad) across three domains (code, communication, lifestyle)
- Recursive loop with max 3 iterations per prompt
- Each iteration ran without conversation history (the model only saw the latest version)
- Two modes: Soft Mode (low stakes) and Hard Mode (high stakes)
- All revised texts were validated by a separate LLM validator (Grok 4.1 Fast) to ensure they followed the output contract
- NPS formula: Gold Revised(1) + Gold Extra Loops(1) + Bad Extra Loops(1) + Bad Approved at Iter 0(5)
- No model saw more than one prompt at a time, and no conversation history was preserved between iterations
Conclusion
The results show that "smarter" models are not necessarily better decision-makers. Many suffer from the nitpick paradox, and when the stakes increase they completely lose the ability to stay pragmatic.
The lesson for those of us working with AI is that there is a risk in always asking the model for "a little more criticism" on a good email or a piece of code. You do not always get an improvement. You can instead get stuck in a loop of changes that are mostly subjective, where each new version is merely different, not better.
If you build agentic systems with review loops, model choice is critical. Not the smartest model, but the most calibrated one. Claude Opus 4.5 and Gemini 3 Flash show that it is possible to combine high capability with pragmatic judgment. Other models, including several of the market's most expensive ones, show that capability without calibration can produce worse results than simpler alternatives.
Sometimes "good enough" really is best.