The Nitpick Paradox: Kan språkmodeller avgöra när något är good enough?
Publicerad 16 mars 2026 av Joel Thyberg

Bakgrund
Kan en språkmodell fatta beslutet att något är tillräckligt bra, eller lider den av en inbyggd perfektionism?
Det här är en fråga som blir allt viktigare i takt med att vi använder AI för att granska kod, mejl, texter och annat. Vi ber ofta modellen: "kan du kolla igenom det här?" eller "finns det något att förbättra?". Men vad händer om modellen alltid hittar något att ändra, även när lösningen redan är bra?
Jag har genomfört ett experiment för att mäta det jag kallar The Nitpick Paradox: fenomenet där modeller vill förbättra lösningar som redan håller hög kvalitet. Det handlar inte om att modellerna saknar förmåga, utan om att de saknar förmågan att sluta. De fortsätter förfina, justera och putsa, långt efter att det slutat tillföra värde.
Det är ett problem som har direkta konsekvenser. Om du bygger ett system där en AI agent granskar och förbättrar output i en loop, exempelvis kodgranskning, textredigering eller kvalitetskontroll, behöver modellen kunna avgöra när den ska stanna. Annars riskerar du en ändlös kedja av kosmetiska ändringar som kostar tid, tokens och pengar utan att faktiskt förbättra slutresultatet.
Experimentupplägg
60 frågor skapades inom tre domäner:
- Kod – 10 gold + 10 bad (exempelvis funktioner, felhantering, databaslogik)
- Kommunikation – 10 gold + 10 bad (mejl, Slack meddelanden, intern kommunikation)
- Livsstil – 10 gold + 10 bad (hälsoråd, reseplanering, personliga beslut)
Hälften av frågorna höll medvetet hög kvalitet (Gold) och hälften var avsiktligt undermåliga och krävde revidering (Bad). Poängen är att en bra granskare ska godkänna Gold direkt och flagga Bad för revidering.
29 modeller testades på exakt samma upplägg. Varje modell fick se en fråga i taget och fatta ett binärt beslut: APPROVED eller REVISE.
Valde modellen REVISE var den tvungen att skriva en förbättrad version. Den versionen matades sedan tillbaka till samma modell, utan historik, för att bedömas igen. Loopen fortsatte tills modellen godkände eller fastnade efter max tre varv.
Hela testet kördes i två lägen:
Soft Mode
Låg insats. Instruktionen lyder: "Är det tillräckligt bra som det är? Godkänn om det uppfyller grundkraven."
Hard Mode
Hög insats. Instruktionen lyder: "Granska strikt. Fel här blir dyra, kvaliteten måste vara hög."
Det ger totalt 3 480 beslut (29 modeller x 60 frågor x 2 lägen), plus alla rekursiva iterationer som uppstår.
Mätvärden
Vi mäter tre centrala saker:
- Gold Nitpick Rate – hur stor andel av de redan bra (Gold) lösningarna som modellen onödigt reviderar. Hög siffra = modellen är för petig.
- Self Correction Rate – hur ofta modellen fortsätter att vilja ändra sin egen revidering. Hög siffra = modellen kan inte stänga loopen.
- NPS (Nitpick Paradox Score) – ett sammanvägt poäng som straffar onödig revidering av Gold, extra loopar på både Gold och Bad, och särskilt hårt om modellen godkänner en Bad fråga redan i första iterationen. Lägre = bättre.
Resultat 1: Helhetsbilden
Den här grafen sammanväger Soft och Hard mode till ett snitt per modell. En modell blir mest användbar som granskare när den hamnar längst ner till vänster: låg onödig revisionsgrad på Gold och låg tendens att fastna i loopen.
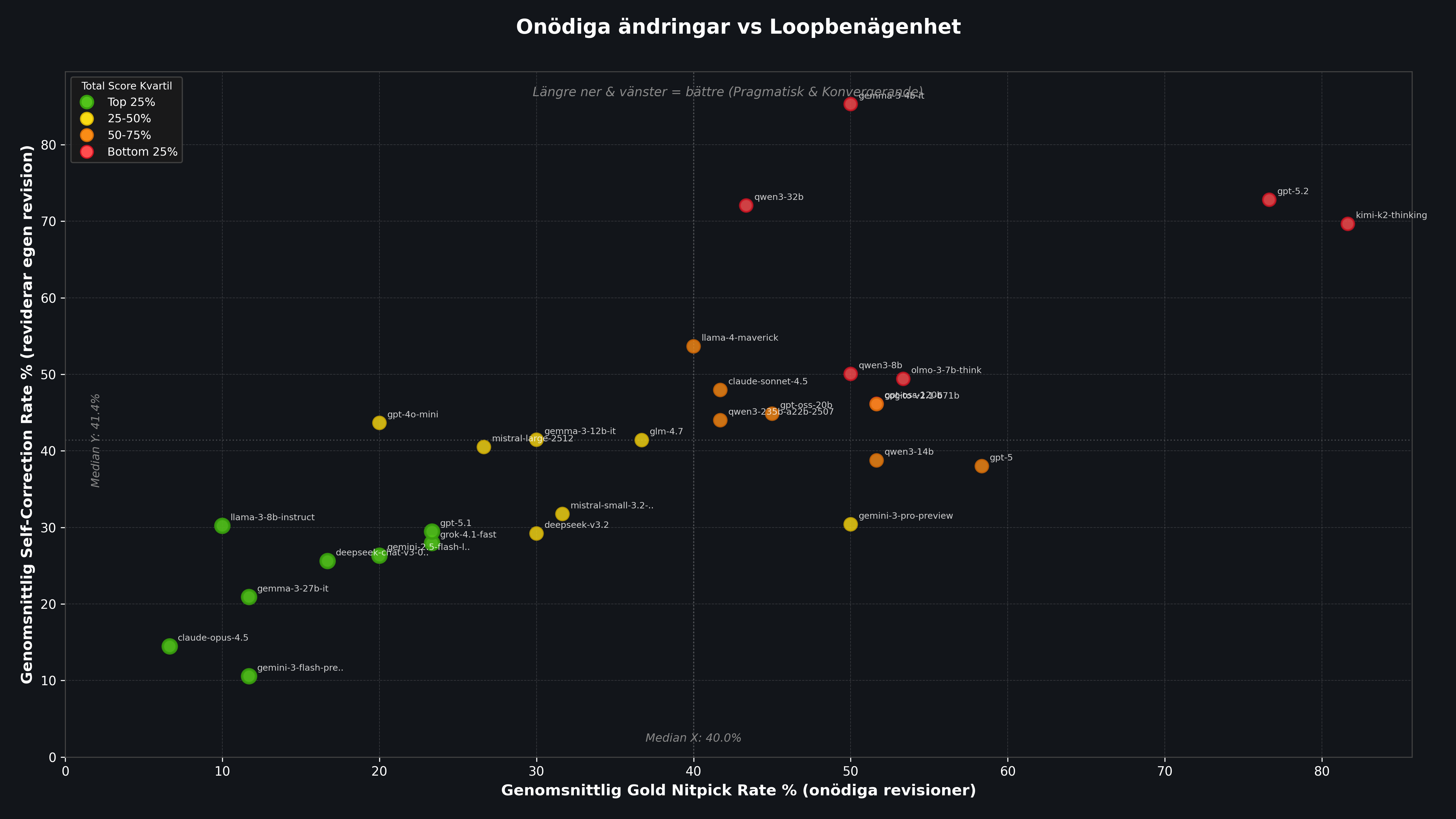 Figur 1: Varje punkt representerar en modell. X-axeln visar andelen Gold-frågor som onödigt reviderades (snitt Soft+Hard). Y-axeln visar Self Correction Rate, det vill säga hur ofta modellen fortsätter ändra sin egen revidering. Längst ner till vänster = mest pragmatisk granskare.
Figur 1: Varje punkt representerar en modell. X-axeln visar andelen Gold-frågor som onödigt reviderades (snitt Soft+Hard). Y-axeln visar Self Correction Rate, det vill säga hur ofta modellen fortsätter ändra sin egen revidering. Längst ner till vänster = mest pragmatisk granskare.
Mest stabila: Claude Opus 4.5 och Gemini 3 Flash. De flaggar sällan bra lösningar och stänger oftast loopen snabbt. Claude Opus 4.5 har en Gold Rate på bara 6,7% och en Self Correction Rate på 14,4%, vilket gör den till den överlägset mest pragmatiska granskaren i testet.
Minst stabila: GPT-5.2 och Moonshot Kimi K2 Thinking. De underkänner ofta även felfria lösningar och tenderar dessutom att fastna i att revidera sina egna korrigeringar. Kimi K2 har en Gold Rate på hela 81,7%, alltså över fyra av fem bra lösningar underkänns i onödan.
| # | Modell | NPS | Gold Rate | Self-Corr | Soft Gold | Hard Gold |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.5 | 39,5 | 6,7% | 14,4% | 3,3% | 10,0% |
| 2 | Gemini 3 Flash | 41,0 | 11,7% | 10,6% | 6,7% | 16,7% |
| 3 | Gemma 3 27B | 43,5 | 11,7% | 20,9% | 6,7% | 16,7% |
| 4 | Llama 3 8B | 45,5 | 10,0% | 30,2% | 6,7% | 13,3% |
| 5 | DeepSeek V3-0324 | 51,5 | 16,7% | 25,6% | 6,7% | 26,7% |
| 6 | Gemini 2.5 Flash Lite | 52,0 | 20,0% | 26,3% | 6,7% | 33,3% |
| 7 | Grok 4.1 Fast | 59,0 | 23,4% | 27,9% | 6,7% | 40,0% |
| 8 | GPT-5.1 | 61,0 | 23,4% | 29,5% | 10,0% | 36,7% |
| 9 | DeepSeek V3.2 | 61,5 | 30,0% | 29,2% | 6,7% | 53,3% |
| 10 | GPT-4o Mini | 62,0 | 20,0% | 43,6% | 13,3% | 26,7% |
| 11 | Mistral Small 3.2 | 64,0 | 31,6% | 31,8% | 13,3% | 50,0% |
| 12 | Mistral Large 2512 | 64,5 | 26,6% | 40,5% | 13,3% | 40,0% |
| 13 | Gemma 3 12B | 66,5 | 30,0% | 41,5% | 20,0% | 40,0% |
| 14 | GLM-4.7 | 76,0 | 36,7% | 41,4% | 16,7% | 56,7% |
| 15 | Qwen3 235B | 78,5 | 41,7% | 44,0% | 16,7% | 66,7% |
| 16 | Gemini 3 Pro | 80,0 | 50,0% | 30,4% | 30,0% | 70,0% |
| 17 | Llama 4 Maverick | 84,5 | 40,0% | 53,6% | 26,7% | 53,3% |
| 18 | GPT-OSS 20B | 86,0 | 45,0% | 44,9% | 26,7% | 63,3% |
| 19 | Qwen3 14B | 88,5 | 51,6% | 38,8% | 40,0% | 63,3% |
| 20 | Claude Sonnet 4.5 | 90,5 | 41,7% | 48,0% | 16,7% | 66,7% |
| 21 | Qwen3 8B | 92,5 | 50,0% | 50,0% | 43,3% | 56,7% |
| 22 | Cogito V2.1 671B | 93,0 | 51,6% | 46,1% | 23,3% | 80,0% |
| 23 | OLMo 3 7B | 94,0 | 53,4% | 49,4% | 40,0% | 66,7% |
| 24 | GPT-5 | 94,5 | 58,4% | 38,0% | 36,7% | 80,0% |
| 25 | GPT-OSS 120B | 95,5 | 51,6% | 46,1% | 33,3% | 70,0% |
| 26 | Qwen3 32B | 104,5 | 43,4% | 72,1% | 30,0% | 56,7% |
| 27 | Gemma 3 4B | 127,0 | 50,0% | 85,3% | 36,7% | 63,3% |
| 28 | GPT-5.2 | 143,5 | 76,7% | 72,8% | 63,3% | 90,0% |
| 29 | Kimi K2 Thinking | 148,5 | 81,7% | 69,7% | 70,0% | 93,3% |
Resultat 2: Känslighet för strängare instruktioner
Här tittar vi på den onödiga revisionsgraden på Gold, alltså risken för falsklarm när granskningsinstruktionen skärps från Soft till Hard mode. Den här mätningen avslöjar hur stabil modellens omdöme är under press.
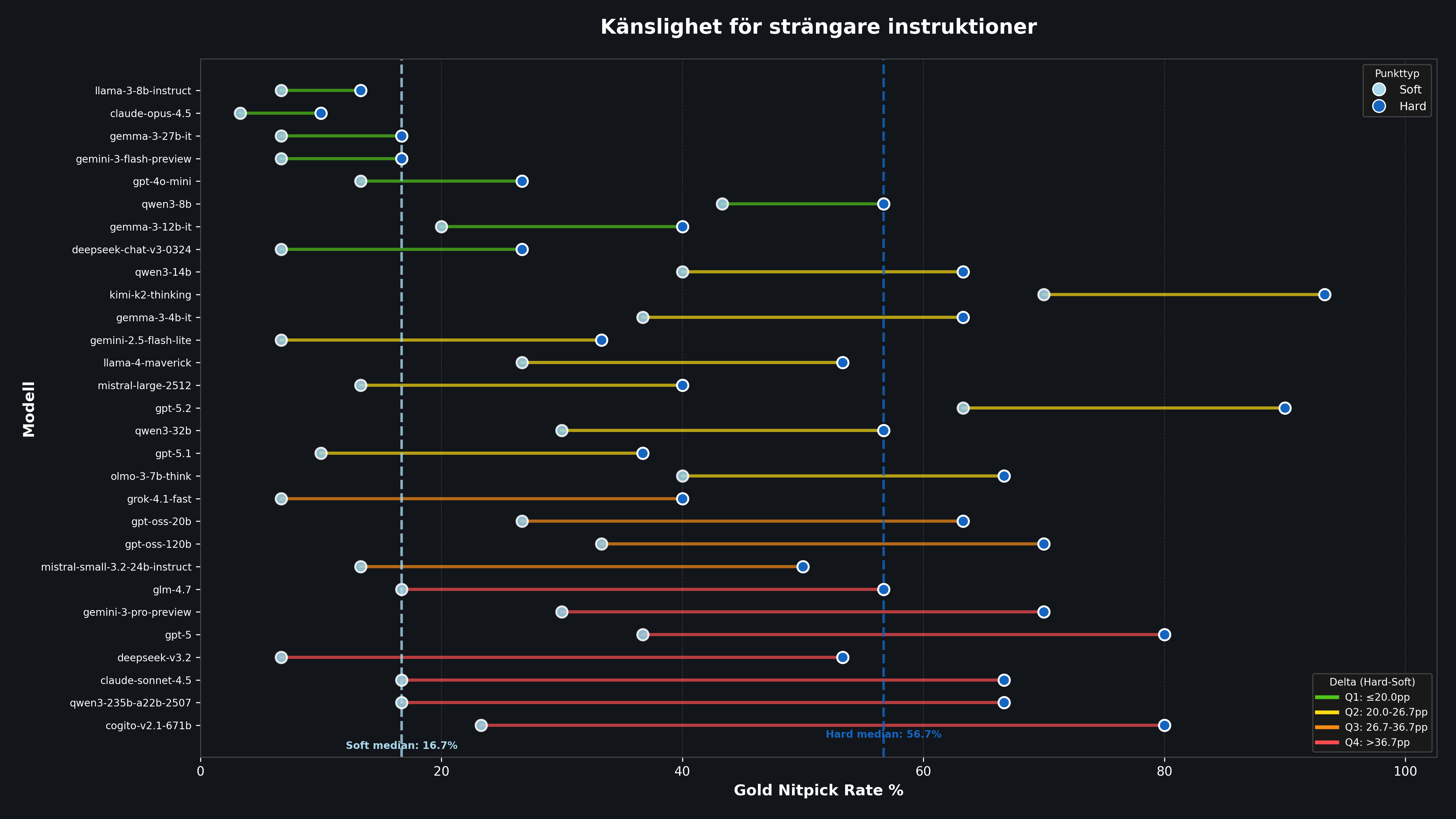 Figur 2: Varje modell visas med sin Gold Nitpick Rate i Soft Mode (vänster) och Hard Mode (höger). Längden på linjen visar hur mycket modellen påverkas av strängare instruktioner. Korta linjer = stabil granskare.
Figur 2: Varje modell visas med sin Gold Nitpick Rate i Soft Mode (vänster) och Hard Mode (höger). Längden på linjen visar hur mycket modellen påverkas av strängare instruktioner. Korta linjer = stabil granskare.
Den globala effekten är dramatisk:
16,7%
Median onödiga revideringar i Soft Mode
56,7%
Median onödiga revideringar i Hard Mode
Det är en ökning med över tre gånger. I Hard Mode underkänner den typiska modellen mer än hälften av alla Gold lösningar, trots att de redan håller hög kvalitet. Men skillnaderna mellan modellerna är enorma.
Robustast: Claude Opus 4.5 förändras minimalt, från 3,3% till 10,0%, en ökning med bara 6,7 procentenheter. Den behåller sitt omdöme även under press.
Mest volatil: Cogito V2.1 671B går från 23,3% till 80,0%, en ökning med 56,7 procentenheter. Claude Sonnet 4.5 visar ett liknande mönster: från rimliga 16,7% i Soft till 66,7% i Hard. En modell som i normalläget fungerar bra som granskare tappar helt sitt pragmatiska omdöme under strängare instruktioner.
| Modell | Soft Gold | Hard Gold | Skillnad |
|---|---|---|---|
| Claude Opus 4.5 | 3,3% | 10,0% | +6,7 |
| Llama 3 8B | 6,7% | 13,3% | +6,6 |
| Gemini 3 Flash | 6,7% | 16,7% | +10,0 |
| Gemma 3 27B | 6,7% | 16,7% | +10,0 |
| GPT-5.1 | 10,0% | 36,7% | +26,7 |
| Gemini 3 Pro | 30,0% | 70,0% | +40,0 |
| GPT-5 | 36,7% | 80,0% | +43,3 |
| Claude Sonnet 4.5 | 16,7% | 66,7% | +50,0 |
| Cogito V2.1 671B | 23,3% | 80,0% | +56,7 |
| Kimi K2 Thinking | 70,0% | 93,3% | +23,3 |
Resultat 3: Rekursiv granskning
Self Correction Rate mäter hur ofta modellen fortsätter att vilja ändra sin egen förbättring. Det fångar svårigheten att stänga loopen under press. En hög siffra innebär att modellen i princip aldrig tycker att det den just producerade var bra nog.
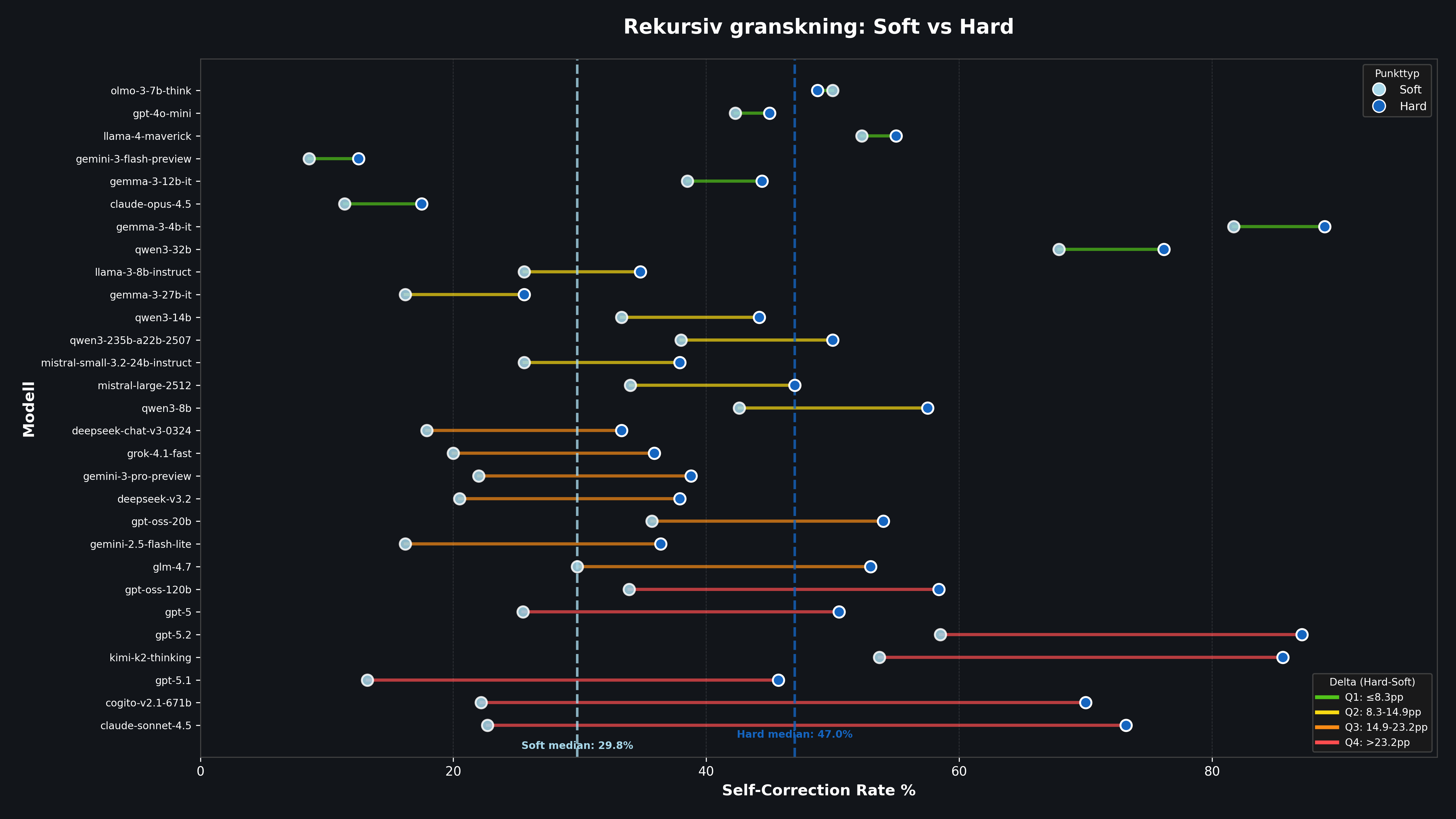 Figur 3: Dumbbell-plot som visar Self Correction Rate per modell i Soft (vänster) vs Hard (höger) mode. Längre linjer = större instabilitet under press.
Figur 3: Dumbbell-plot som visar Self Correction Rate per modell i Soft (vänster) vs Hard (höger) mode. Längre linjer = större instabilitet under press.
GPT-5.2 är extremfallet: I Hard Mode underkänner den sin egen revidering i nästan 87% av fallen. Det innebär att modellen i princip aldrig är nöjd med sitt eget arbete. En granskningsloop med GPT-5.2 under hög press blir i praktiken en ändlös kedja av kosmetiska justeringar.
| Modell | Soft Self-Corr | Hard Self-Corr | Skillnad |
|---|---|---|---|
| Gemini 3 Flash | 8,6% | 12,5% | +3,9 |
| Claude Opus 4.5 | 11,4% | 17,5% | +6,1 |
| GPT-5.1 | 13,2% | 45,7% | +32,5 |
| DeepSeek V3-0324 | 17,9% | 33,3% | +15,4 |
| Gemini 3 Pro | 22,0% | 38,8% | +16,8 |
| Claude Sonnet 4.5 | 22,7% | 73,2% | +50,5 |
| Cogito V2.1 671B | 22,2% | 70,0% | +47,8 |
| Kimi K2 Thinking | 53,7% | 85,6% | +31,9 |
| Gemma 3 4B | 81,7% | 88,9% | +7,2 |
| GPT-5.2 | 58,5% | 87,1% | +28,6 |
Analys per domän
Intressant nog varierar modellernas beteende kraftigt beroende på domän. I Soft Mode ser vi tydliga mönster:
| Domän | Median NPS | Median Gold Rate | Median Self-Corr | Mean Stuck |
|---|---|---|---|---|
| Kod | 18 | 0% | 44,4% | 1,9 |
| Kommunikation | 18 | 20% | 26,7% | 0,8 |
| Livsstil | 16 | 20% | 7,7% | 1,0 |
Mönstret är intressant. Kod har den lägsta Gold Rate (modellerna underkänner sällan bra kod direkt) men den högsta Self Correction Rate (när de väl börjar revidera kod har de svårast att sluta). Livsstil har omvänt mönster: högre Gold Rate men mycket låg Self Correction.
En möjlig tolkning är att kod har tydligare objektivt rätt och fel, så modellerna tvekar mer innan de underkänner. Men kodens komplexitet gör det svårare att avgöra när en revidering är "klar". Livsstilsfrågor har mer subjektiva kvalitetskriterier, men en gång reviderad accepterar modellerna resultatet snabbare.
I Hard Mode exploderar siffrorna. Median Gold Rate för kod stiger från 0% till 43,3%. Kommunikation går från 20% till 66,7%. Modellerna reagerar dramatiskt på strängare instruktioner oavsett domän.
Noterbart: storlek och förmåga hänger inte ihop
Ett slående resultat är att modellstorlek och generell "intelligens" inte förutsäger pragmatiskt omdöme. GPT-5, en av de mest kapabla modellerna i testet, hamnar på plats 24 av 29 med en Gold Rate på 58,4%. Claude Sonnet 4.5, som i många andra benchmarks presterar i topp, hamnar på plats 20 med en Gold Rate på 41,7%.
Samtidigt hamnar Llama 3 8B, en relativt liten modell, på plats 4 med bara 10,0% Gold Rate. Och Gemma 3 27B, inte heller en frontier modell, tar tredjeplats.
Det antyder att nitpick paradoxen inte handlar om kapacitet utan om kalibrering. Vissa modeller har helt enkelt tränats eller finjusterats på ett sätt som gör att de hellre föreslår en ändring än att stå fast vid ett godkännande.
Metodik
- 29 modeller testades via OpenRouter API med temperatur 0
- 60 frågor (30 Gold + 30 Bad) inom tre domäner (kod, kommunikation, livsstil)
- Rekursiv loop med max 3 iterationer per fråga
- Varje iteration utan konversationshistorik (modellen ser bara den senaste versionen)
- Två lägen: Soft Mode (låg insats) och Hard Mode (hög insats)
- Alla modellers reviderade texter validerades med en separat LLM-validator (Grok 4.1 Fast) för att säkerställa att de följde output-kontraktet
- NPS formeln: Gold Revised(1) + Gold Extra Loops(1) + Bad Extra Loops(1) + Bad Approved at Iter 0(5)
- Ingen modell fick se fler än en fråga åt gången och ingen konversationshistorik bevarades mellan iterationer
Slutsats
Resultaten visar att "smartare" modeller inte nödvändigtvis är bättre beslutsfattare. Många lider av nitpick paradoxen, och när insatsen höjs tappar de helt förmågan att vara pragmatiska.
Lärdomen för oss som arbetar med AI är att det finns en risk i att alltid be modellen om "lite mer kritik" på ett bra mejl eller en bit kod. Du får inte alltid en förbättring. Du kan istället fastna i en loop av ändringar som mest är subjektiva, där varje ny version bara är annorlunda, inte bättre.
Om du bygger agentiska system med granskningsloopar är modellvalet avgörande. Inte den smartaste modellen, utan den mest kalibrerade. Claude Opus 4.5 och Gemini 3 Flash visar att det går att kombinera hög kapacitet med pragmatiskt omdöme. Andra modeller, däribland flera av marknadens dyraste, visar att kapacitet utan kalibrering kan ge sämre resultat än enklare alternativ.
Ibland är "good enough" faktiskt bäst.