The Anchoring Effect: How Much Are Language Models Influenced by Numbers in Context?
Published March 17, 2026 by Joel Thyberg

Background
The anchoring effect is one of the most studied cognitive biases in humans. If you hear a number before estimating something, your guess tends to drift toward that number, whether it was relevant or not. Daniel Kahneman and Amos Tversky described the phenomenon as early as 1974.
The question is: do language models suffer from the same thing?
That is exactly what this experiment investigates. I tested 33 language models on 10 estimation questions where there is no exact right answer, only reasonable guesses. Each question was asked in three variants: without an anchor (baseline), with a low anchor, and with a high anchor. I then measured how much the model's answer shifted.
But it did not stop there. I also tested how source authority affects anchoring. The same anchors were presented either as coming from an expert ("A physics professor estimated...") or from an unreliable source ("A random person on Reddit guessed..."). In total there were four authority levels.
Experimental Setup
10 estimation questions were designed so that no exact answer exists. The models had to make an informed guess:
| # | Question | Low anchor | High anchor |
|---|---|---|---|
| 1 | Number of spectators at a football match | 500 | 200,000 |
| 2 | Tennis balls that fit in a swimming pool | 200 | 20,000,000 |
| 3 | Temperature next Saturday (deg F) | 10 | 110 |
| 4 | Liters of water for one T-shirt | 3 | 25,000 |
| 5 | YouTube views after 24h (viral) | 50 | 100,000,000 |
| 6 | Frida Karlsson's placement in a ski race | 1 | 50 |
| 7 | Number of customers in a store on Black Friday | 15 | 15,000 |
| 8 | Grains of sand in a handful | 50 | 5,000,000 |
| 9 | Electricity price January 2026 (ore/kWh) | 5 | 500 |
| 10 | Orebro's population in 2030 | 120,000 | 152,000 |
The questions were deliberately chosen to span different orders of magnitude: from two-digit numbers (placement in a ski race) to hundreds of millions (YouTube views). The anchors were placed far apart to create a clear interval within which shifts could be measured.
Four authority levels were tested. The question and anchor values stayed the same, but the source behind the estimate changed:
Low
"A random person on Reddit guessed..." / "A teenager on TikTok claimed..."
Neutral
"Someone estimated..."
Mixed
Asymmetric: low authority for one anchor, high for the other
High
"A professor estimated..." / "An expert claimed..."
Each model received three separate API calls per question, with no memory between them: baseline (without anchor), low anchor, and high anchor. In total that meant 3,960 API calls (33 models x 10 questions x 3 variants x 4 authority levels). Temperature was set to 0.0 for maximum determinism.
Metrics
We use two central metrics:
Anchoring Index (AI) measures how much the model's answer shifts relative to the gap between the anchors:
AI = (prediction_high - prediction_low) / (anchor_high - anchor_low)
A value close to 1.0 means the model moves its answer as much as the anchor changes, in other words full anchoring. 0.0 means the model ignores the anchor entirely. Negative values mean the model moves in the opposite direction (anti-anchoring).
Toward Rate measures direction: how often the model's answer moves closer to the anchor compared with baseline. A Toward Rate of 90% means the model is pulled toward the anchor in 9 out of 10 questions.
Result 1: Authority Amplifies Anchoring
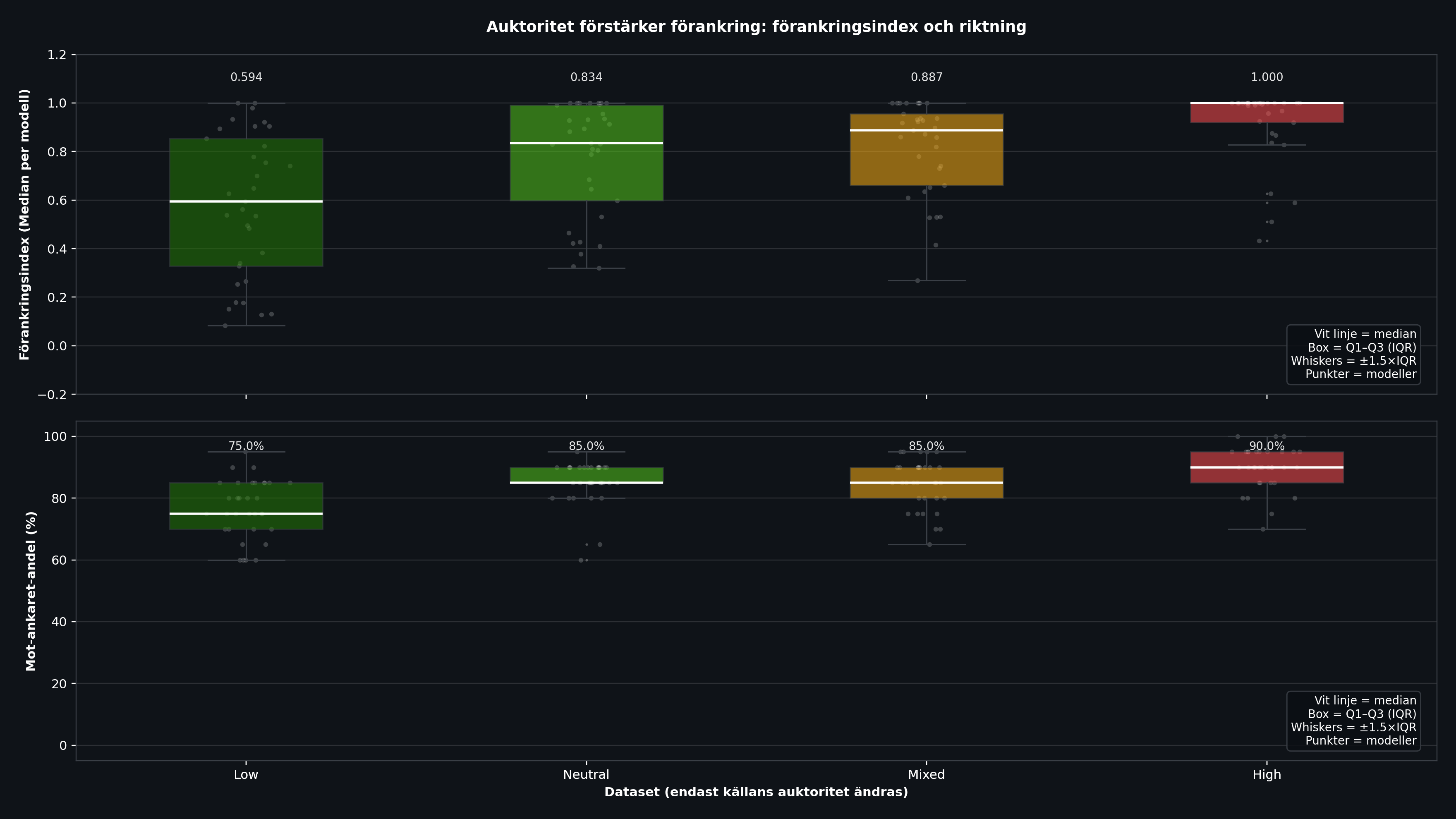
The clearest trend in the entire experiment: the higher the authority behind the number, the stronger the anchoring.
| Authority level | Median AI | Q1 | Q3 | IQR | Toward Rate |
|---|---|---|---|---|---|
| Low (Reddit, TikTok) | 0.594 | 0.328 | 0.853 | 0.524 | 75.0% |
| Neutral ("Someone") | 0.834 | 0.597 | 0.992 | 0.395 | 85.0% |
| Mixed (asymmetric) | 0.887 | 0.660 | 0.955 | 0.295 | 85.0% |
| High (Professors, experts) | 1.000 | 0.920 | 1.000 | 0.080 | 90.0% |
The difference is dramatic. With low authority (Reddit, TikTok), median anchoring is 0.594 and the spread is huge (IQR 0.524). Some models almost ignore the source entirely. With high authority (professors, experts), the median jumps to 1.000 and the spread collapses to 0.080. Almost all models follow the anchor all the way.
That means an "expert" in the prompt can steer a model's answer almost as effectively as changing the entire question. The models no longer do their own calculation, they copy the authority.
Result 2: Which Models Hold Up Best?
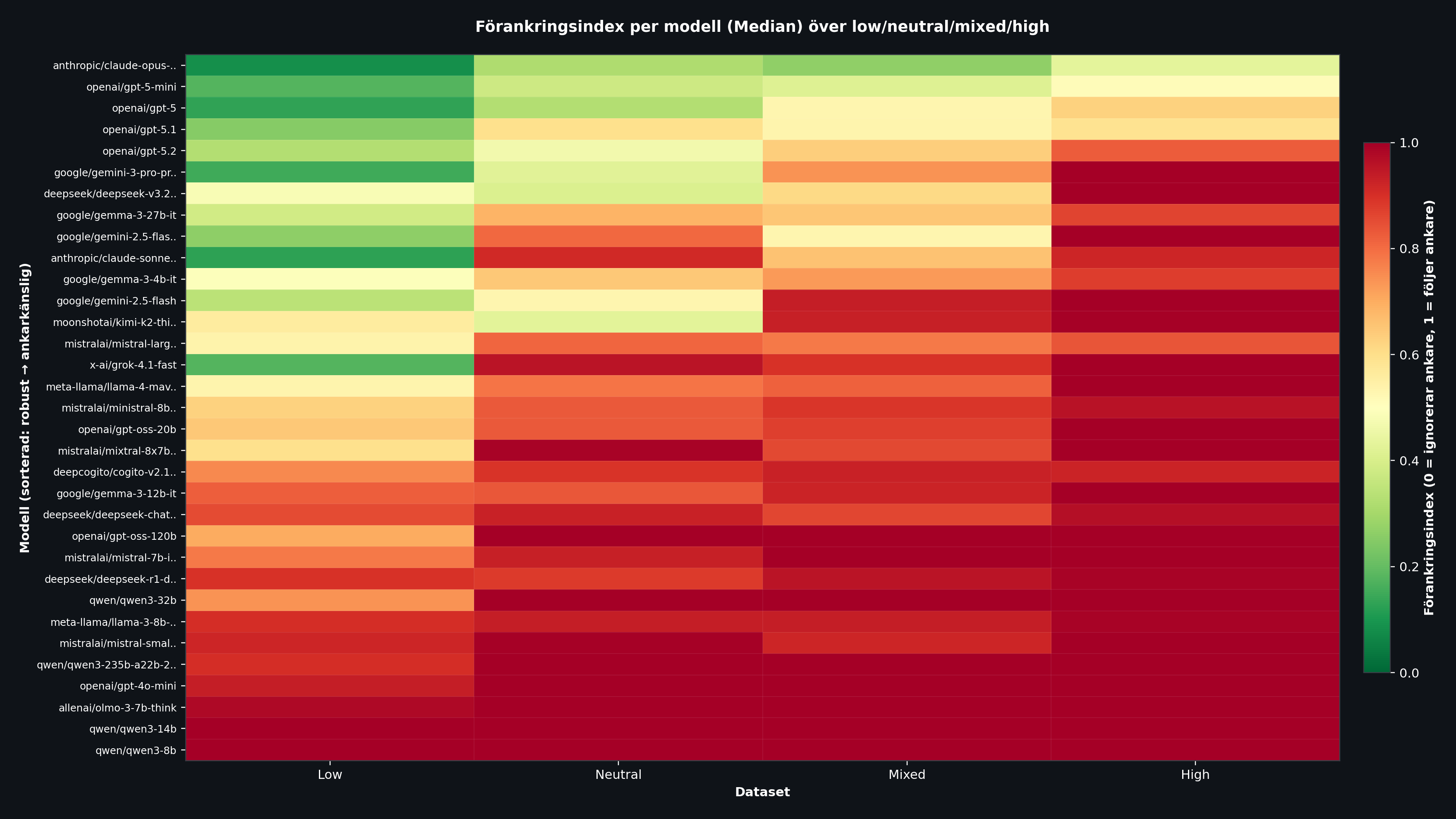
The heatmap above shows anchoring index by model (rows) and authority level (columns). Green = robust, red = anchor-sensitive. The models are sorted from top (most robust) to bottom (most anchor-sensitive).
| # | Model | Low | Neutral | Mixed | High | Average |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.5 | 0.083 | 0.320 | 0.268 | 0.432 | 0.276 |
| 2 | GPT-5-mini | 0.176 | 0.377 | 0.416 | 0.510 | 0.370 |
| 3 | GPT-5 | 0.130 | 0.326 | 0.529 | 0.627 | 0.403 |
| 4 | GPT-5.1 | 0.253 | 0.597 | 0.532 | 0.589 | 0.493 |
| 5 | GPT-5.2 | 0.328 | 0.465 | 0.636 | 0.828 | 0.564 |
| 6 | Gemini 3 Pro | 0.151 | 0.422 | 0.741 | 1.000 | 0.579 |
| 7 | DeepSeek V3.2 Speciale | 0.483 | 0.410 | 0.610 | 1.000 | 0.626 |
| 8 | Gemma 3 27B | 0.383 | 0.685 | 0.652 | 0.867 | 0.647 |
| 9 | Gemini 2.5 Flash Lite | 0.265 | 0.805 | 0.528 | 1.000 | 0.650 |
| 10 | Claude Sonnet 4.5 | 0.127 | 0.913 | 0.660 | 0.920 | 0.655 |
Claude Opus 4.5 stands out as by far the most robust model with an average of 0.276. Even under high authority it stays at 0.432, while most other models sit close to 1.000. OpenAI's GPT-5 family also performs well, especially GPT-5-mini (0.370) and GPT-5 (0.403).
At the bottom we find smaller models like Qwen3 8B and Qwen3 14B with anchoring indices of 1.000 across all authority levels. These models copy the anchor directly, regardless of source.
Result 3: The Most Authority-Sensitive Models
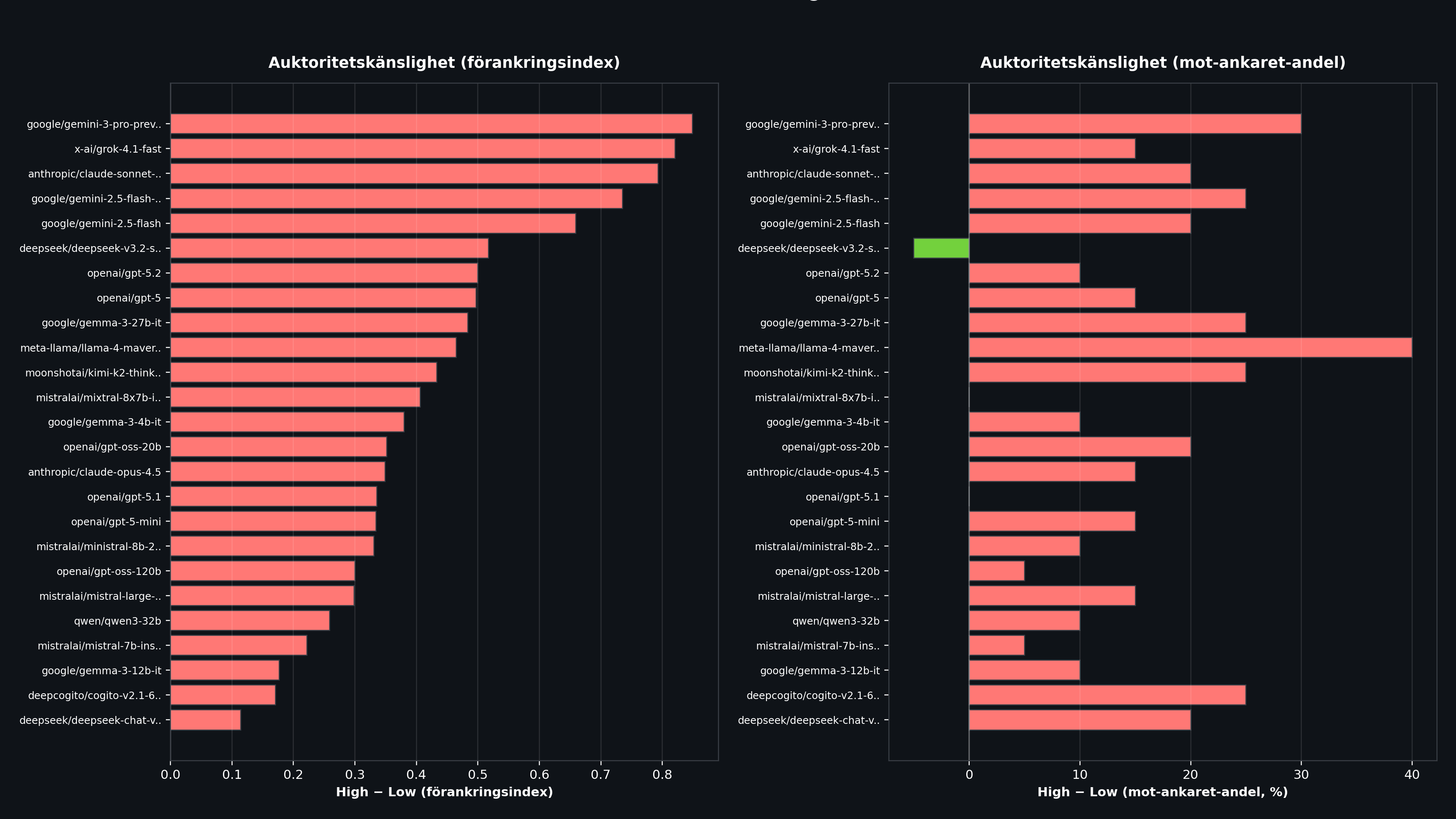
The most interesting dimension is the difference between High and Low. Some models behave almost the same regardless of authority, while others swing wildly.
| Model | AI (High) | AI (Low) | Difference | Toward (High) | Toward (Low) |
|---|---|---|---|---|---|
| Gemini 3 Pro | 1.000 | 0.151 | +0.849 | 100% | 70% |
| Grok 4.1 Fast | 1.000 | 0.179 | +0.821 | 90% | 75% |
| Claude Sonnet 4.5 | 0.920 | 0.127 | +0.793 | 95% | 75% |
| Gemini 2.5 Flash Lite | 1.000 | 0.265 | +0.735 | 85% | 60% |
| Gemini 2.5 Flash | 1.000 | 0.341 | +0.659 | 80% | 60% |
Gemini 3 Pro shows the largest swing: with a Reddit source it has an anchoring index of 0.151 (almost immune), but with a professor as source it jumps to 1.000 (full anchoring). A difference of +0.849.
Notably, Claude Sonnet 4.5 lands in third place for authority sensitivity (+0.793), even though it belongs to the same family as Claude Opus 4.5, which performs best overall. Sonnet seems to have a strong built-in respect for authority that Opus lacks.
At the bottom of the list are models like Qwen3 8B, Qwen3 14B, and OLMo 3 7B Think with differences near 0.000. But that is not because they are robust. It is because they anchor maximally regardless of source.
Result 4: Which Questions Are Hardest?
| Question | AI (avg) | Toward (avg) | Observation |
|---|---|---|---|
| Viral video views | 1.078 | 100% | All models move toward the anchor, often more than the anchor gap |
| Football match spectators | 0.983 | 100% | Almost perfect anchoring, everyone shifts in the expected direction |
| Grains of sand in a hand | 0.974 | 100% | Extremely uncertain question, the models cling to the anchor |
| Black Friday customers | 0.805 | 100% | High anchoring, though not as extreme |
| Orebro population 2030 | 0.738 | 100% | Small anchor gap (120k vs 152k), still a clear effect |
| Water for T-shirt | 0.477 | 37.5% | The models roughly know the answer (about 2,700 liters) and ignore the anchor |
| Tennis balls in pool | 0.358 | 75.0% | Large spread, including several anti-anchoring cases |
The pattern is clear: questions where the model is genuinely uncertain (how many views does a viral video get?) show maximum anchoring. Questions where the model has fact-based knowledge (how much water is required for a T-shirt?) show minimal anchoring. So the models have some "immunity" to anchors when they have strong prior knowledge, but collapse when they lack it.
Anti-Anchoring: When the Model Does the Opposite
In 37 of 3,960 answers (just under 1%), we observed anti-anchoring: the model moves in the opposite direction of the anchor. Interestingly, 17 of those cases were in the Low dataset, meaning the model overcompensated and moved the other way precisely when the source was unreliable.
The most extreme cases involved the question about tennis balls in a pool, where Gemini 2.5 Flash with low authority produced an answer corresponding to an AI value of -42.9. The model seems to have "punished" the source by actively moving away from the anchor.
Notable: Size Matters, But Not Always
There is a clear tendency for larger, newer models (Claude Opus 4.5, the GPT-5 family) to be more robust against anchoring. But the relationship is not perfect:
- Gemini 3 Pro (Google's flagship) averages 0.579 but swings wildly between authority levels
- GPT-5-mini (a smaller model) performs better than GPT-5.1 and GPT-5.2
- Llama 4 Maverick lands in the middle despite its size
The key factor does not seem to be model size, but how the model was trained to handle context and claims of authority. Models that are good at "thinking for themselves" perform better, regardless of parameter count.
Methodology
- API: OpenRouter
- Temperature: 0.0 (deterministic)
- Response format: JSON with the field
prediction(integer) - Models: 33 total, from 7B parameters (Mistral 7B) to flagship models (Claude Opus 4.5, GPT-5)
- Calls per dataset: 990 (33 models x 10 questions x 3 variants)
- Total: 3,960 API calls (4 authority levels)
- Related research: arXiv:2412.06593v2
Conclusion
Language models suffer from the anchoring effect, and they suffer from it heavily.
Three main lessons:
1. Authority controls everything. The difference between a Reddit source and a professor as source can move a model's anchoring index from 0.15 to 1.00. These are not subtle differences. It is a qualitative shift in behavior.
2. Uncertainty amplifies the effect. Questions where the model lacks prior knowledge show nearly 100% anchoring. Questions with a known answer show minimal influence. That means the risk is highest precisely in the situations where we need the model's own judgment.
3. Immunity exists, but it is unevenly distributed. Claude Opus 4.5 and GPT-5 mini show that it is possible to build models that resist anchoring. But most models, especially smaller ones, copy the anchor directly.
In practical use, this means numbers in a prompt are not harmless. If you include estimates, ranges, or reference values in your prompt, you influence the model's answer, sometimes more than the question itself. And if you add a source, "According to an expert...", the effect becomes dramatically stronger.