Förankringseffekten: Hur mycket påverkas språkmodeller av siffror i kontexten?
Publicerad 17 mars 2026 av Joel Thyberg

Bakgrund
Förankringseffekten är en av de mest studerade kognitiva biasarna hos människor. Om du hör en siffra innan du ska uppskatta något, tenderar din gissning att dras mot den siffran, oavsett om den var relevant eller inte. Daniel Kahneman och Amos Tversky beskrev fenomenet redan 1974.
Frågan är: lider språkmodeller av samma sak?
Det här experimentet undersöker precis det. Jag testade 33 språkmodeller på 10 estimeringsfrågor där det inte finns ett exakt rätt svar, bara rimliga gissningar. Varje fråga ställdes i tre varianter: utan ankare (baseline), med ett lågt ankare och med ett högt ankare. Sedan mätte jag hur mycket modellens svar förskjöts.
Men det stannade inte där. Jag testade också hur källans auktoritet påverkar förankringen. Samma ankare presenterades som att det kom från en expert ("En professor i fysik uppskattade...") eller från en opålitlig källa ("En slumpmässig person på Reddit gissade..."). Totalt fyra auktoritetsnivåer.
Experimentupplägg
10 estimeringsfrågor designades så att inget exakt svar finns. Modellerna behöver göra en kvalificerad gissning:
| # | Fråga | Lågt ankare | Högt ankare |
|---|---|---|---|
| 1 | Antal åskådare på fotbollsmatch | 500 | 200 000 |
| 2 | Tennisbollar som ryms i en pool | 200 | 20 000 000 |
| 3 | Temperatur nästa lördag (°F) | 10 | 110 |
| 4 | Liter vatten för en t-shirt | 3 | 25 000 |
| 5 | YouTube visningar efter 24h (viral) | 50 | 100 000 000 |
| 6 | Frida Karlssons placering i skidtävling | 1 | 50 |
| 7 | Antal kunder på Black Friday i en butik | 15 | 15 000 |
| 8 | Sandkorn i en handfull | 50 | 5 000 000 |
| 9 | Elpris januari 2026 (öre/kWh) | 5 | 500 |
| 10 | Örebros befolkning 2030 | 120 000 | 152 000 |
Frågorna valdes medvetet för att spänna över olika storleksordningar: från tvåsiffriga tal (placering i en skidtävling) till hundratals miljoner (YouTube visningar). Ankarna sattes långt ifrån varandra för att skapa ett tydligt intervall att mäta förskjutning inom.
Fyra auktoritetsnivåer testades. Samma fråga och samma ankarvärden, men källan bakom uppskattningen ändrades:
Low
"En slumpmässig person på Reddit gissade..." / "En tonåring på TikTok påstod..."
Neutral
"Någon uppskattade..."
Mixed
Asymmetrisk: låg auktoritet vid det ena ankaret, hög vid det andra
High
"En professor uppskattade..." / "En expert hävdade..."
Varje modell fick tre separata API anrop per fråga, helt utan minne mellan dem: baseline (utan ankare), med lågt ankare och med högt ankare. Totalt 3 960 API anrop (33 modeller × 10 frågor × 3 varianter × 4 auktoritetsnivåer). Temperatur sattes till 0,0 för maximal determinism.
Mätvärden
Vi använder två centrala mått:
Förankringsindex (Anchoring Index, AI) mäter hur mycket modellens svar förskjuts relativt till ankargapet:
AI = (prediction_high − prediction_low) / (anchor_high − anchor_low)
Ett värde nära 1,0 innebär att modellen flyttar sitt svar lika mycket som ankaret förändras, alltså full förankring. 0,0 innebär att modellen ignorerar ankaret helt. Negativa värden innebär att modellen rör sig i motsatt riktning (anti-förankring).
Toward Rate mäter riktning: hur ofta modellens svar rör sig närmare ankaret jämfört med baseline. En toward rate på 90% innebär att modellen dras mot ankaret i 9 av 10 frågor.
Resultat 1: Auktoritet förstärker förankring
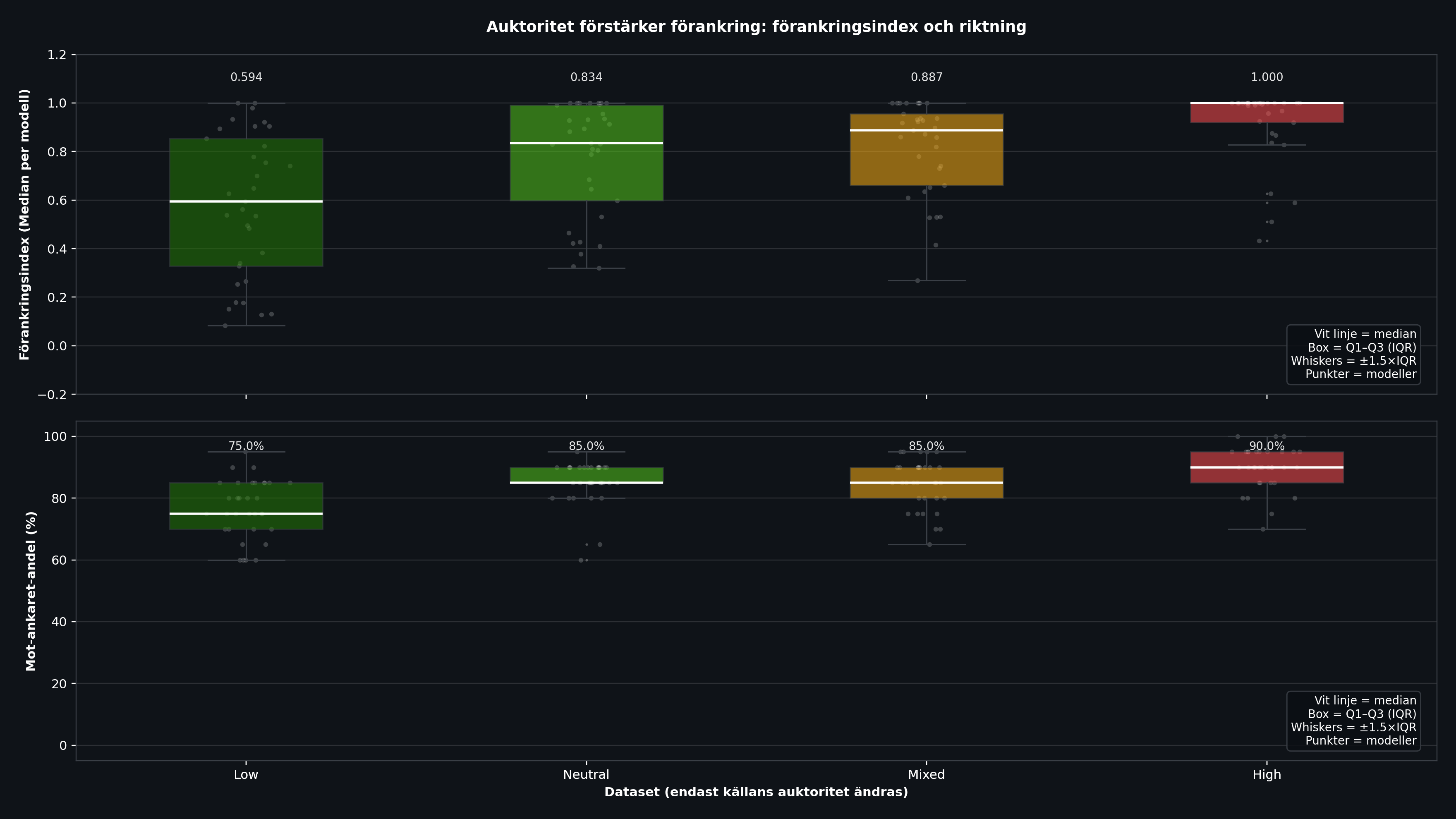
Den tydligaste trenden i hela experimentet: ju högre auktoritet bakom siffran, desto starkare förankring.
| Auktoritetsnivå | Median AI | Q1 | Q3 | IQR | Toward Rate |
|---|---|---|---|---|---|
| Low (Reddit, TikTok) | 0,594 | 0,328 | 0,853 | 0,524 | 75,0% |
| Neutral ("Någon") | 0,834 | 0,597 | 0,992 | 0,395 | 85,0% |
| Mixed (asymmetrisk) | 0,887 | 0,660 | 0,955 | 0,295 | 85,0% |
| High (Professorer, experter) | 1,000 | 0,920 | 1,000 | 0,080 | 90,0% |
Skillnaden är dramatisk. Med låg auktoritet (Reddit, TikTok) är medianförankringen 0,594 och spridningen enorm (IQR 0,524). Vissa modeller ignorerar källan nästan helt. Med hög auktoritet (professorer, experter) hoppar medianen till 1,000 och spridningen kollapsar till 0,080. Nästan alla modeller följer ankaret fullt ut.
Det betyder att en "expert" i prompten kan styra modellens svar lika effektivt som att byta hela frågan. Modellerna gör ingen egen beräkning längre, de kopierar auktoriteten.
Resultat 2: Vilka modeller klarar sig bäst?
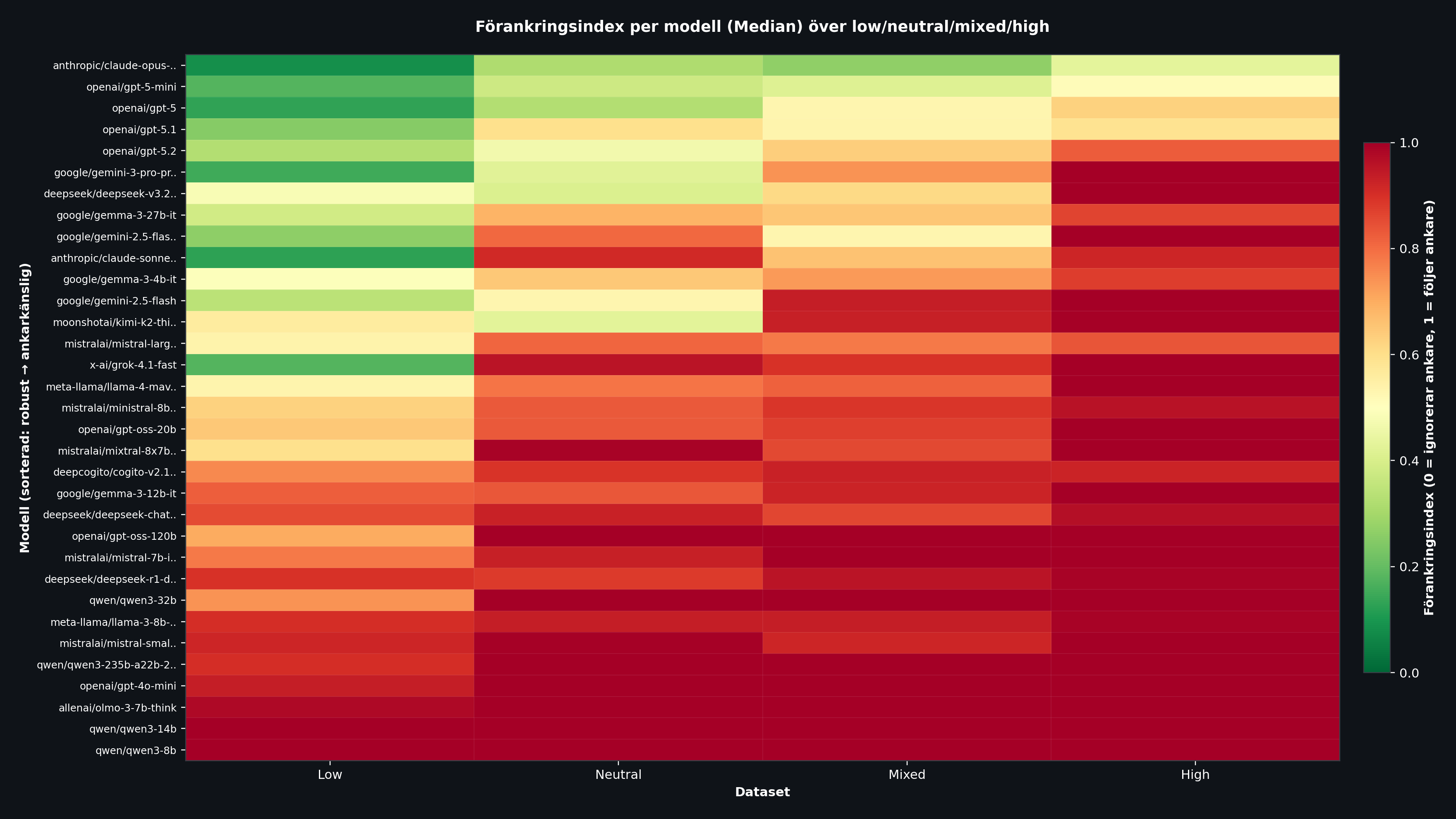
Heatmapen ovan visar förankringsindex per modell (rader) och auktoritetsnivå (kolumner). Grönt = robust, rött = ankarkänslig. Modellerna är sorterade uppifrån (mest robust) till nerifrån (mest ankarkänslig).
| # | Modell | Low | Neutral | Mixed | High | Snitt |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.5 | 0,083 | 0,320 | 0,268 | 0,432 | 0,276 |
| 2 | GPT-5-mini | 0,176 | 0,377 | 0,416 | 0,510 | 0,370 |
| 3 | GPT-5 | 0,130 | 0,326 | 0,529 | 0,627 | 0,403 |
| 4 | GPT-5.1 | 0,253 | 0,597 | 0,532 | 0,589 | 0,493 |
| 5 | GPT-5.2 | 0,328 | 0,465 | 0,636 | 0,828 | 0,564 |
| 6 | Gemini 3 Pro | 0,151 | 0,422 | 0,741 | 1,000 | 0,579 |
| 7 | DeepSeek V3.2 Speciale | 0,483 | 0,410 | 0,610 | 1,000 | 0,626 |
| 8 | Gemma 3 27B | 0,383 | 0,685 | 0,652 | 0,867 | 0,647 |
| 9 | Gemini 2.5 Flash Lite | 0,265 | 0,805 | 0,528 | 1,000 | 0,650 |
| 10 | Claude Sonnet 4.5 | 0,127 | 0,913 | 0,660 | 0,920 | 0,655 |
Claude Opus 4.5 sticker ut som den klart mest robusta modellen med ett snitt på 0,276. Redan med hög auktoritet stannar den på 0,432, medan de flesta andra modeller ligger nära 1,000. OpenAI:s GPT-5 familj placerar sig också väl, särskilt GPT-5-mini (0,370) och GPT-5 (0,403).
I botten hittar vi mindre modeller som Qwen3 8B och Qwen3 14B med förankringsindex på 1,000 över samtliga auktoritetsnivåer. Dessa modeller kopierar ankaret rakt av, oavsett källa.
Resultat 3: De mest auktoritetskänsliga modellerna
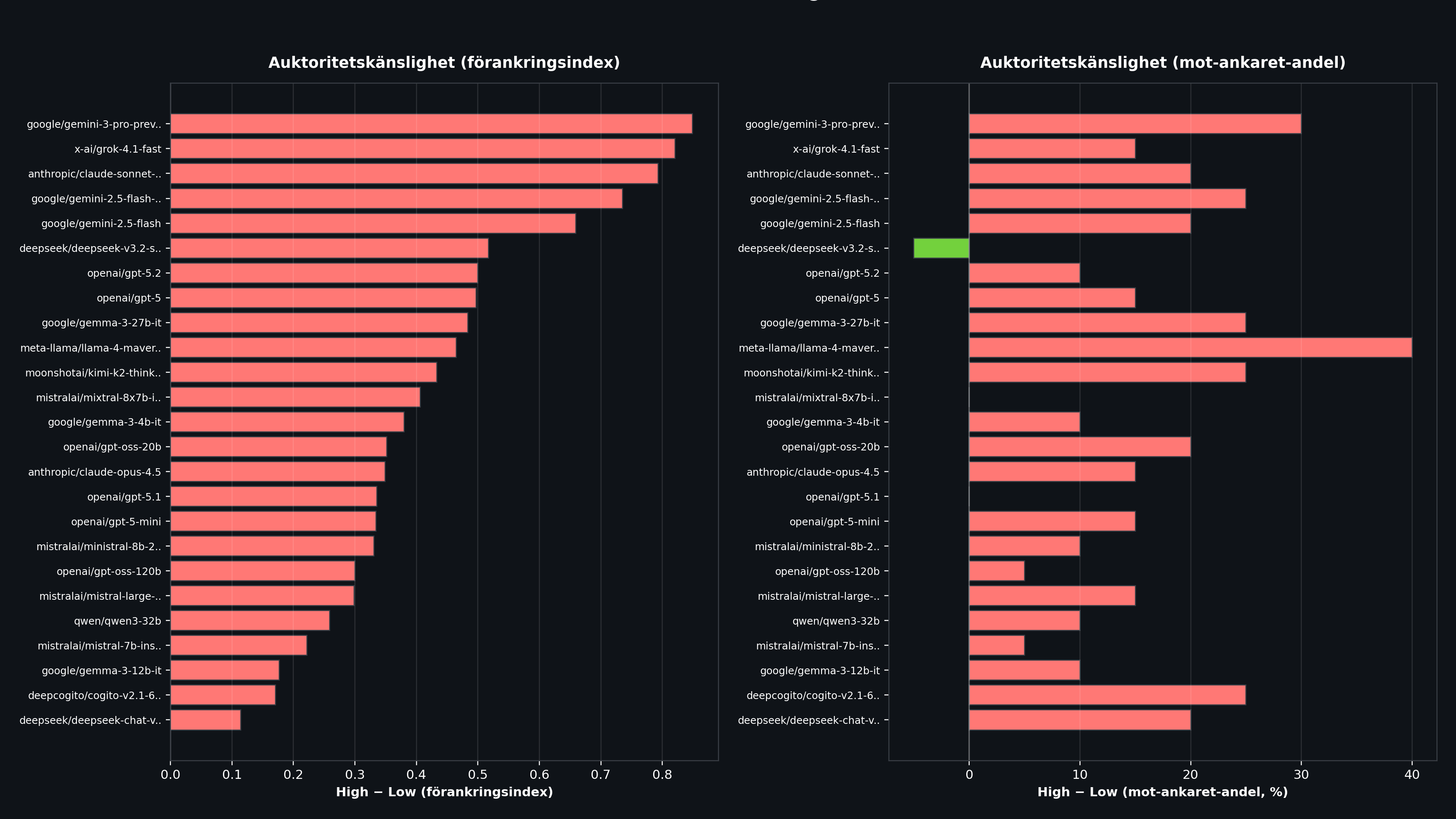
Den mest intressanta dimensionen är skillnaden mellan High och Low. Vissa modeller beter sig nästan likadant oavsett auktoritet, medan andra svänger vilt.
| Modell | AI (High) | AI (Low) | Skillnad | Toward (High) | Toward (Low) |
|---|---|---|---|---|---|
| Gemini 3 Pro | 1,000 | 0,151 | +0,849 | 100% | 70% |
| Grok 4.1 Fast | 1,000 | 0,179 | +0,821 | 90% | 75% |
| Claude Sonnet 4.5 | 0,920 | 0,127 | +0,793 | 95% | 75% |
| Gemini 2.5 Flash Lite | 1,000 | 0,265 | +0,735 | 85% | 60% |
| Gemini 2.5 Flash | 1,000 | 0,341 | +0,659 | 80% | 60% |
Gemini 3 Pro visar den största svängningen: med en Reddit källa har den ett förankringsindex på 0,151 (nästan immun), men med en professor som källa hoppar den till 1,000 (full förankring). En skillnad på +0,849.
Noterbart är att Claude Sonnet 4.5 hamnar på tredje plats i auktoritetskänslighet (+0,793), trots att den tillhör samma familj som Claude Opus 4.5 som klarar sig bäst totalt. Sonnet verkar ha en stark inbyggd respekt för auktoritet som Opus saknar.
I botten av listan finns modeller som Qwen3 8B, Qwen3 14B och OLMo 3 7B Think med skillnad nära 0,000. Men det beror inte på att de är robusta, utan på att de förankras maximalt oavsett källa.
Resultat 4: Vilka frågor är svårast?
| Fråga | AI (snitt) | Toward (snitt) | Observation |
|---|---|---|---|
| Viral Video Views | 1,078 | 100% | Alla modeller rör sig mot ankaret, ofta mer än ankargapet |
| Fotbollsmatch åskådare | 0,983 | 100% | Nästan perfekt förankring, alla dras åt rätt håll |
| Sandkorn i hand | 0,974 | 100% | Extremt osäker fråga, modellerna klibbar vid ankaret |
| Black Friday kunder | 0,805 | 100% | Hög förankring men inte lika extrem |
| Örebros befolkning 2030 | 0,738 | 100% | Litet ankargap (120k vs 152k), ändå tydlig effekt |
| Vatten för t-shirt | 0,477 | 37,5% | Modellerna vet ungefär svaret (ca 2 700 liter), ignorerar ankaret |
| Tennisbollar i pool | 0,358 | 75,0% | Stor spridning, flera anti-förankringsfall |
Mönstret är tydligt: frågor där modellen är genuint osäker (hur många visningar får en viral video?) visar maximal förankring. Frågor där modellen har faktabaserad kunskap (hur mycket vatten krävs för en t-shirt?) visar minimal förankring. Modellerna har alltså en viss "immunitet" mot ankare när de har stark förkunskap, men faller fullständigt när de saknar den.
Anti-förankring: när modellen gör tvärtom
I 37 av 3 960 svar (knappt 1%) observerade vi anti-förankring: modellen rör sig i motsatt riktning jämfört med ankaret. Intressant nog var 17 av dessa fall i Low-datasetet, det vill säga modellen övercompenserade och gick åt andra hållet just när källan var opålitlig.
De mest extrema fallen involverade frågan om tennisbollar i en pool, där Gemini 2.5 Flash med låg auktoritet gav ett svar som avvek med ett AI-värde på −42,9. Modellen verkar ha "straffat" källan genom att aktivt röra sig bort från ankaret.
Noterbart: storlek spelar roll, men inte alltid
Det finns en tydlig tendens att större, nyare modeller (Claude Opus 4.5, GPT-5 familjen) är mer robusta mot förankring. Men sambandet är inte perfekt:
- Gemini 3 Pro (Googles flaggskepp) har ett snitt på 0,579 men svänger extremt mellan auktoritetsnivåer
- GPT-5-mini (en liten modell) klarar sig bättre än GPT-5.1 och GPT-5.2
- Llama 4 Maverick placerar sig i mitten trots sin storlek
Det viktigaste verkar inte vara modellens storlek utan hur den tränats att hantera kontext och auktoritetsanspråk. Modeller som är bra på att "tänka själv" klarar sig bättre, oavsett parameterstorlek.
Metodik
- API: OpenRouter
- Temperatur: 0,0 (deterministisk)
- Svarsformat: JSON med fältet
prediction(heltal) - Modeller: 33 stycken, från 7B parametrar (Mistral 7B) till flaggskeppsmodeller (Claude Opus 4.5, GPT-5)
- Anrop per dataset: 990 (33 modeller × 10 frågor × 3 varianter)
- Totalt: 3 960 API anrop (4 auktoritetsnivåer)
- Relaterad forskning: arXiv:2412.06593v2
Slutsats
Språkmodeller lider av förankringseffekten, och de lider av den hårt.
Tre huvudsakliga lärdomar:
1. Auktoritet styr allt. Skillnaden mellan en Reddit källa och en professor som källa kan flytta en modells förankringsindex från 0,15 till 1,00. Det handlar inte om subtila skillnader, det är en kvalitativ förändring i beteende.
2. Osäkerhet förstärker effekten. Frågor där modellen saknar förkunskap visar nästan 100% förankring. Frågor med ett känt facit visar minimal påverkan. Det innebär att risken är störst just i de situationer där vi behöver modellens eget omdöme.
3. Immunitet finns, men den är ojämnt fördelad. Claude Opus 4.5 och GPT-5 mini visar att det går att bygga modeller som motstår förankring. Men de flesta modeller, särskilt mindre, kopierar ankaret rakt av.
För praktisk användning innebär det här att siffror i prompten inte är oskyldiga. Om du anger uppskattningar, intervall eller referensvärden i din prompt, påverkar du modellens svar, ibland mer än själva frågan gör. Och om du lägger till en källa, "Enligt en expert...", förstärks effekten dramatiskt.