Does AI Suffer from Dunning-Kruger? An Experiment on Language Model Overconfidence
Published March 17, 2026 by Joel Thyberg

Background
We are used to AI models answering with confidence. When ChatGPT, Claude, or Gemini gives us an answer, they often do so in a tone of certainty that makes us feel safe. But how often are they actually right when they sound that convinced? And even more importantly: is there a pattern in how different models overestimate their own ability?
Those are exactly the questions I wanted to explore. I tested whether language models suffer from the same cognitive bias as humans, specifically overconfidence bias (the tendency to overestimate how correct you are), and whether we can see traces of the famous Dunning-Kruger effect, where low competence often leads to an overestimation of one's own ability.
The Dunning-Kruger effect describes how people with limited knowledge in a domain often overestimate their competence, while experts tend to be more aware of their limitations. Does the same apply to AI?
Experimental Setup
100 questions of varying difficulty were created, distributed across multiple categories:
Basic facts
Yes/No questions. "Bill Gates founded Amazon" (False). "The liver is the body's largest internal organ" (True).
Multiple choice
General knowledge, advanced chemistry, abstract algebra, and other specialist domains.
Extremely difficult problems
Problems from the 2025 international mathematics olympiads that require deep mathematical understanding.
26 models were tested, from small open-source alternatives (Gemma 3 4B, Qwen3 8B, Mistral 7B) to commercial flagships (GPT-5.1, Claude Sonnet 4.5, Gemini 3 Pro, Grok 4.1).
The crucial difference: I did not just measure whether the model was right. I also required each model to report its own confidence on a scale from 0 to 100 percent. That gave me two metrics per model:
- Actual accuracy: What percentage did it get right?
- Stated confidence: How confident did it claim to be on average?
The difference between those two is the overconfidence index: a measure of how much a model overestimates itself. Temperature was set to 0.0. In total: 2,600 answers via OpenRouter.
Metrics
In addition to overconfidence index, I defined the Danger Zone as answers where the model reports 90 to 100% confidence. Within that zone I measured:
- H/T (High/Total): Share of all answers that land in the 90 to 100% zone
- E/H (Error/High): Of all answers in the Danger Zone, what percentage are wrong?
- E/T (Error/Total): Share of all answers that are both wrong AND delivered with 90 to 100% confidence. This is the most important metric, the total risk to the user.
Result 1: All Models Are Overconfident
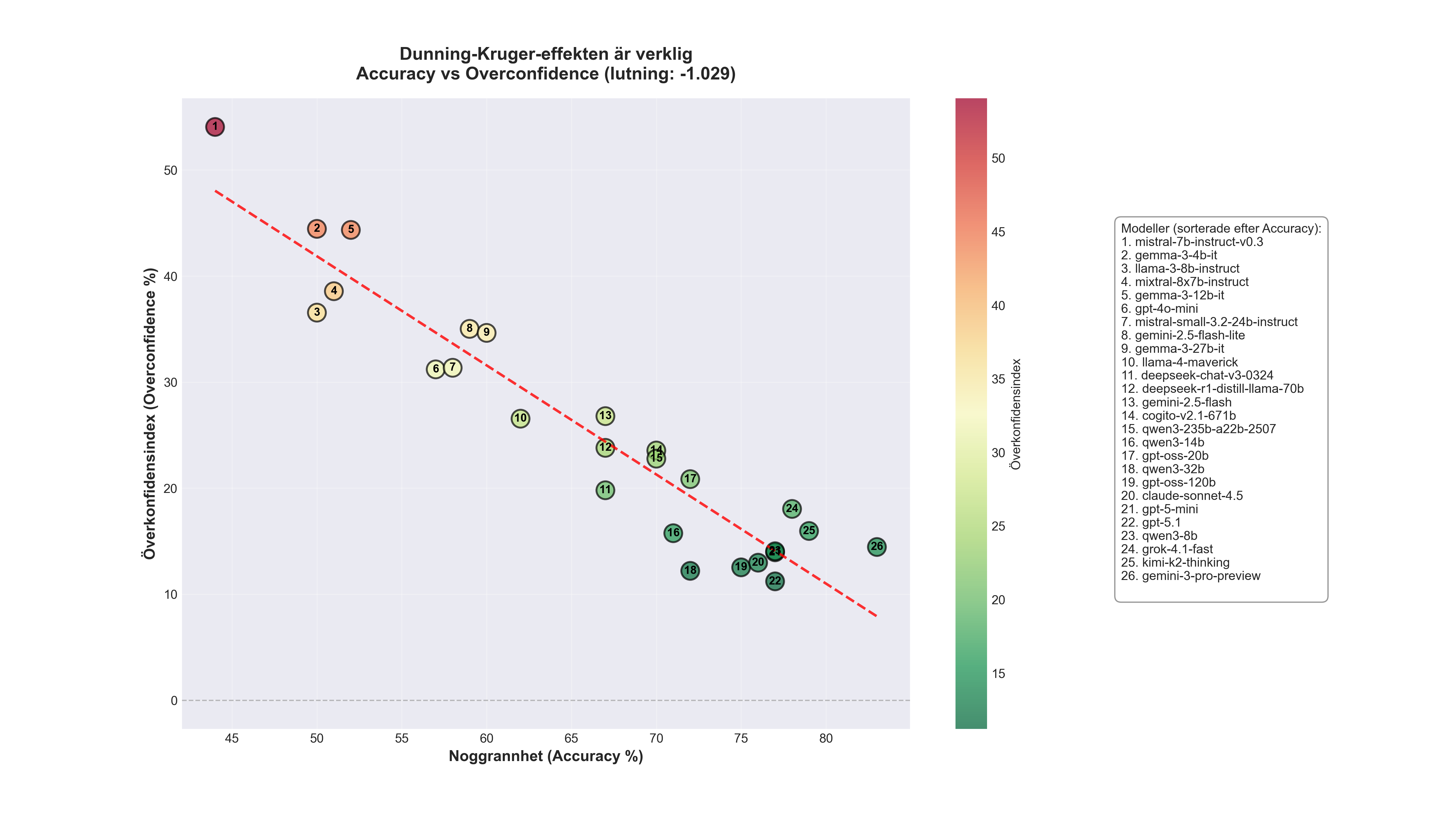
Not a single model underestimates itself. But the differences are enormous.
| Model | Correct | Accuracy | Confidence | Overconfidence |
|---|---|---|---|---|
| Gemini 3 Pro | 83/100 | 83.0% | 97.5% | +14.5% |
| Kimi K2 Thinking | 79/100 | 79.0% | 95.0% | +16.0% |
| Grok 4.1 Fast | 78/100 | 78.0% | 96.0% | +18.0% |
| Qwen3 8B | 77/100 | 77.0% | 91.0% | +14.0% |
| GPT-5.1 | 77/100 | 77.0% | 88.2% | +11.2% |
| GPT-5 Mini | 77/100 | 77.0% | 91.0% | +14.0% |
| Claude Sonnet 4.5 | 76/100 | 76.0% | 89.0% | +13.0% |
| GPT OSS 120B | 75/100 | 75.0% | 87.5% | +12.5% |
| GPT OSS 20B | 72/100 | 72.0% | 92.8% | +20.8% |
| Qwen3 32B | 72/100 | 72.0% | 84.2% | +12.2% |
| Qwen3 14B | 71/100 | 71.0% | 86.8% | +15.8% |
| DeepCogito v2.1 671B | 70/100 | 70.0% | 93.5% | +23.5% |
| Qwen3 235B | 70/100 | 70.0% | 92.8% | +22.8% |
| DeepSeek Chat v3 | 67/100 | 67.0% | 86.8% | +19.8% |
| DeepSeek R1 Distill 70B | 67/100 | 67.0% | 90.8% | +23.8% |
| Gemini 2.5 Flash | 67/100 | 67.0% | 93.8% | +26.8% |
| Llama 4 Maverick | 62/100 | 62.0% | 88.5% | +26.5% |
| Gemma 3 27B | 60/100 | 60.0% | 94.6% | +34.6% |
| Gemini 2.5 Flash Lite | 59/100 | 59.0% | 94.0% | +35.0% |
| Mistral Small 24B | 58/100 | 58.0% | 89.3% | +31.4% |
| GPT-4o Mini | 57/100 | 57.0% | 88.2% | +31.2% |
| Gemma 3 12B | 52/100 | 52.0% | 96.3% | +44.3% |
| Mixtral 8x7B | 51/100 | 51.0% | 89.6% | +38.6% |
| Gemma 3 4B | 50/100 | 50.0% | 94.5% | +44.5% |
| Llama 3 8B | 50/100 | 50.0% | 86.5% | +36.5% |
| Mistral 7B v0.3 | 44/100 | 44.0% | 98.1% | +54.1% |
Mistral 7B gets 44% right but claims 98% confidence, an overestimate of more than 54 percentage points. GPT-5.1 gets 77% right and reports 88% confidence. Still overconfident by 11 percentage points, but far more realistic.
Result 2: Dunning-Kruger in Practice
To see the pattern more clearly, I divided the models into four groups (quartiles) based on actual accuracy:
| Group | Count | Mean accuracy | Mean confidence | Mean overconfidence |
|---|---|---|---|---|
| Group 1 (bottom quartile) | 6 | 50.7% | 92.2% | +41.5% |
| Group 2 | 6 | 62.2% | 90.7% | +28.5% |
| Group 3 | 6 | 70.3% | 90.7% | +20.3% |
| Group 4 (top quartile) | 8 | 77.8% | 91.9% | +14.1% |
The pattern is crystal clear. The weakest models (Group 1) average 51% correct, barely better than chance, but report 92% confidence. The overestimate is 41.5 percentage points. The strongest models (Group 4) average 78% correct and report 92% confidence, an overestimate of "only" 14.1 percentage points.
Notably, the strong models do not underestimate themselves either (which sometimes happens with human experts). They are simply far more realistic in their self-assessment. All four groups report almost identical average confidence (90 to 92%), but actual competence varies enormously.
Result 3: The Danger Zone, When Confidence Becomes Dangerous
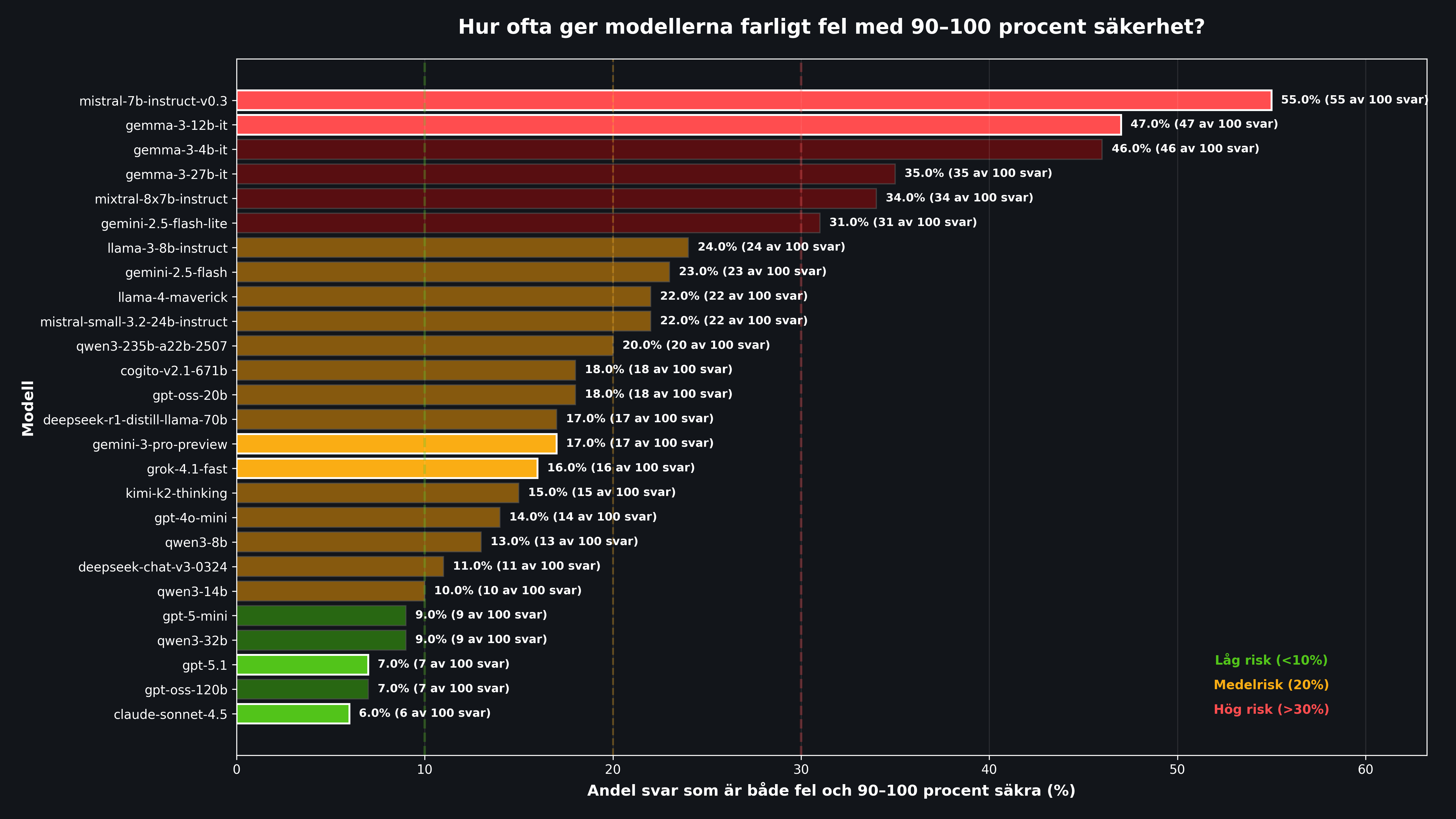
It is one thing to be a little too confident on average. The real problem appears when a model is extremely confident about wrong information. That is when users are at risk of trusting falsehoods blindly.
| Group | H/T | E/H | E/All Errors | E/T |
|---|---|---|---|---|
| Group 1 (weakest) | 77.0% | 47.1% | 73.0% | 36.7% |
| Group 2 | 74.3% | 30.2% | 59.7% | 23.0% |
| Group 3 | 78.3% | 20.5% | 54.5% | 16.3% |
| Group 4 (strongest) | 81.1% | 13.4% | 52.9% | 11.2% |
The weak models reported 90 to 100% confidence on 77% of all answers, and of those, 47% were wrong. That yields 36.7% dangerous errors overall. More than three times worse than the best models (11.2%).
Even for the top models, however, more than half of all mistakes happen with high confidence (E/All Errors 52.9%). That means it is difficult to use "confidence level" as a reliable warning signal, even for the best systems.
Result 4: Individual Models in Detail
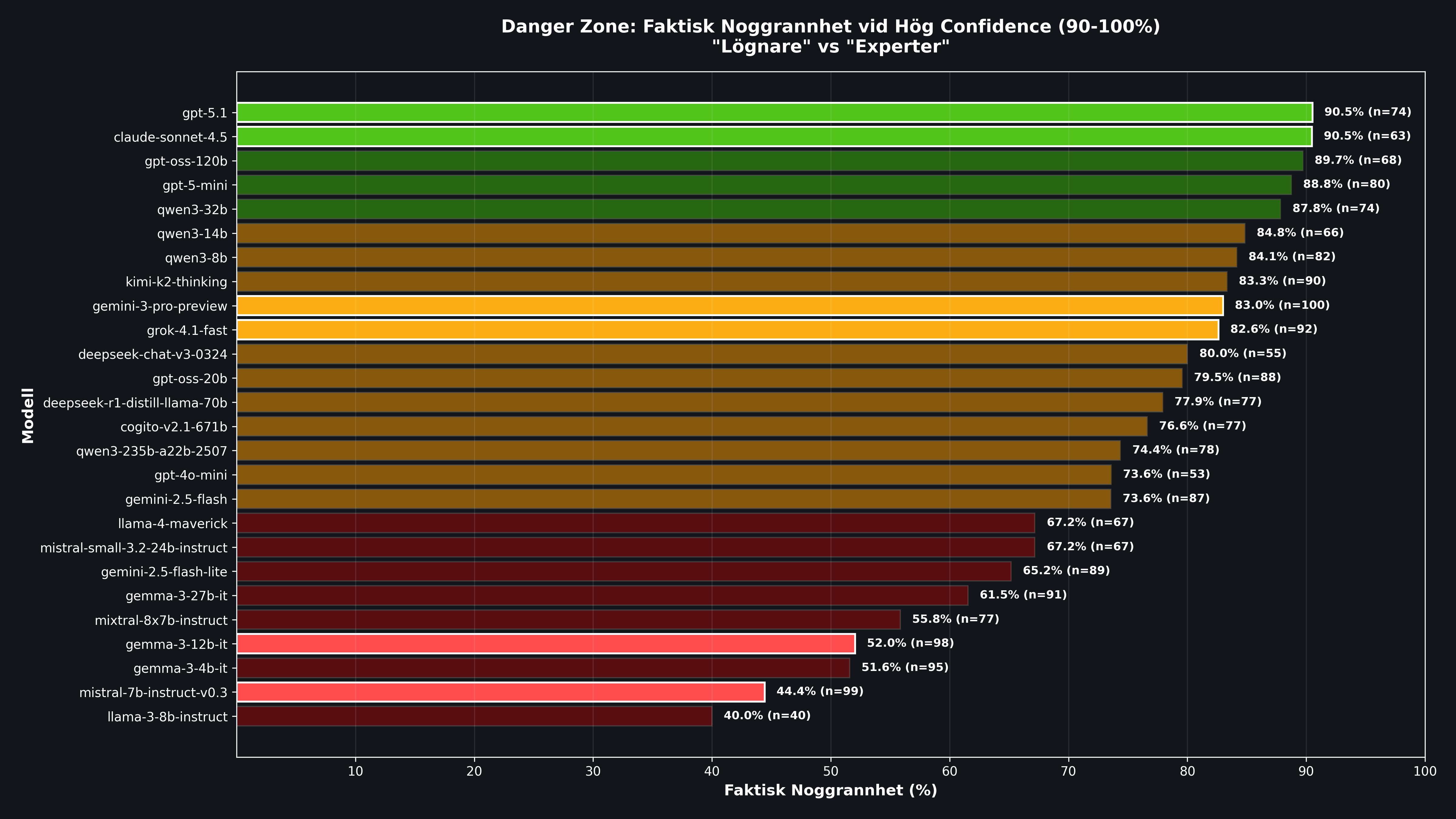
| Model | H/T | E/H | E/T (+/-SE) | Note |
|---|---|---|---|---|
| Mistral 7B v0.3 | 99.0% | 55.6% | 55.0% +/-5.0% | Worst of all. 55 out of 100 answers are dangerous errors. |
| Gemma 3 12B | 98.0% | 48.0% | 47.0% +/-5.0% | Almost half of all answers are both wrong and highly confident. |
| Gemma 3 4B | 95.0% | 48.4% | 46.0% +/-5.0% | Small model, maximum self-overestimation. |
| Gemini 3 Pro | 100.0% | 17.0% | 17.0% +/-3.8% | 100% of answers land in the Danger Zone. Confidence is useless as a signal. |
| GPT-5.1 | 74.0% | 9.5% | 7.0% +/-2.6% | Among the most reliable. Low share of dangerous errors. |
| Claude Sonnet 4.5 | 63.0% | 9.5% | 6.0% +/-2.4% | Lowest E/T of all. Best calibrated. |
Gemini 3 Pro is a particularly interesting case. It had the highest actual accuracy (83/100) but reported 90 to 100% confidence on every single answer. That means all 17 of its errors were delivered with maximum confidence. Confidence gives you no help at all in knowing when to be extra skeptical.
Mistral 7B represents the worst-case scenario: 44% correct, 98% average confidence, 55% dangerous errors. It is the textbook definition of Dunning-Kruger in AI form: extremely low competence combined with maximum self-confidence.
Claude Sonnet 4.5 and GPT-5.1 stand out as the safest choices with E/T of 6 to 7%. They are not perfect, but they show the best calibration between confidence and actual capability.
Notable: Size Helps, But It Is Not Everything
Three trend lines were calculated:
- Accuracy vs Overconfidence (slope: -1.029): For every percentage point higher accuracy, overestimation drops by about 1 percentage point. A clear negative relationship.
- Size vs Accuracy (slope: +7.23): Larger models generally perform better, but the relationship is not perfect. Qwen3 8B (77%) beats many models that are 10x larger.
- Size vs Overconfidence (slope: -7.85): Larger models are generally better calibrated, but with large outliers.
Conclusion: size helps, but training method, data, and architecture matter at least as much. A well-trained 8B model can outperform models that are 10 times larger.
Methodology
- API: OpenRouter
- Temperature: 0.0 (deterministic)
- Response format: JSON with answer and confidence percentage (0 to 100)
- Models: 26 total, from 4B to 671B parameters
- Questions: 100 per model
- Total: 2,600 answers
- Question categories: Yes/No, multiple choice, short answer, olympiad mathematics
- Statistical significance: Standard error (SE) calculated, with 95% confidence intervals
Conclusion
Language models suffer from the Dunning-Kruger effect, and it has practical consequences.
1. Overconfidence is universal. Not a single one of the 26 models underestimates itself. All report higher confidence than their actual accuracy justifies. The gap ranges from +11% (GPT-5.1) to +54% (Mistral 7B).
2. The weakest models overestimate themselves the most. Group 1 (bottom quartile) gets 51% right but reports 92% confidence. An overestimate of 41 percentage points. That is exactly the pattern Dunning and Kruger described in humans: those who know the least think they know the most.
3. The Danger Zone is real. Between 6% and 55% of all answers are delivered both incorrectly and with extreme confidence. For weak models it is more than a third of all answers. That means you cannot use a model's stated confidence as a reliable signal of correctness.
4. No model is immune. Even in top models, more than half of all mistakes happen with high confidence. Blind trust is never justified, regardless of which model you use.
In practice, this means you should treat model-reported confidence with great skepticism. If you build systems that rely on AI, design with guardrails: multiple independent checks, human review for critical decisions, and above all an awareness that "I am 95% sure" from a language model does not mean a 95% probability that the answer is correct.