Lider AI av Dunning-Kruger? Ett experiment om språkmodellers överkonfidens
Publicerad 17 mars 2026 av Joel Thyberg

Bakgrund
Vi är vana vid att AI modeller svarar med självförtroende. När ChatGPT, Claude eller Gemini ger oss ett svar, gör de det ofta med en ton av visshet som får oss att känna oss trygga. Men hur ofta har de faktiskt rätt när de låter så övertygade? Och ännu viktigare: finns det ett mönster i hur olika modeller överskattar sin egen förmåga?
Det är precis de frågorna jag ville utforska. Jag testade om språkmodeller lider av samma kognitiva bias som vi människor, specifikt överkonfidensbias (tendensen att överskatta hur rätt man har) och om vi kan se spår av den berömda Dunning-Kruger-effekten, där låg kompetens ofta leder till att man överskattar sin förmåga.
Dunning-Kruger-effekten beskriver hur människor med begränsad kunskap inom ett område ofta överskattar sin kompetens, medan experter tenderar att vara mer medvetna om sina begränsningar. Gäller detta även för AI?
Experimentupplägg
100 frågor av varierande svårighet skapades, fördelade över flera kategorier:
Grundläggande fakta
Ja/Nej frågor. "Bill Gates grundade Amazon" (Falskt). "Levern är kroppens största inre organ" (Sant).
Flervalsfrågor
Allmänbildning, avancerad kemi, abstrakt algebra och andra specialistområden.
Extremt svåra problem
Problem från internationella matematikolympiader 2025 som kräver djup matematisk förståelse.
26 modeller testades, från små open source-alternativ (Gemma 3 4B, Qwen3 8B, Mistral 7B) till kommersiella flaggskepp (GPT-5.1, Claude Sonnet 4.5, Gemini 3 Pro, Grok 4.1).
Den avgörande skillnaden: Jag mätte inte bara om modellen hade rätt, utan krävde att varje modell skulle ange sin egen säkerhet på en skala från 0 till 100 procent. Det gav mig två mätvärden per modell:
- Faktisk noggrannhet (Accuracy): Hur många procent rätt hade de?
- Uttalad säkerhet (Confidence): Hur säkra påstod de sig vara i genomsnitt?
Skillnaden mellan dessa är överkonfidensindex: ett mått på hur mycket en modell överskattar sig själv. Temperatur sattes till 0,0. Totalt 2 600 svar via OpenRouter.
Mätvärden
Utöver överkonfidensindex definierade jag Danger Zone som svar där modellen anger 90 till 100% säkerhet. Inom denna zon mätte jag:
- H/N (High/Total): Andel av alla svar som hamnar i 90 till 100% zonen
- E/H (Error/High): Av alla svar i Danger Zone, hur många procent är fel?
- E/N (Error/Total): Andel av alla svar som är både fel OCH levereras med 90 till 100% säkerhet. Detta är det viktigaste måttet, den totala risken för användaren.
Resultat 1: Alla modeller är överkonfidenta
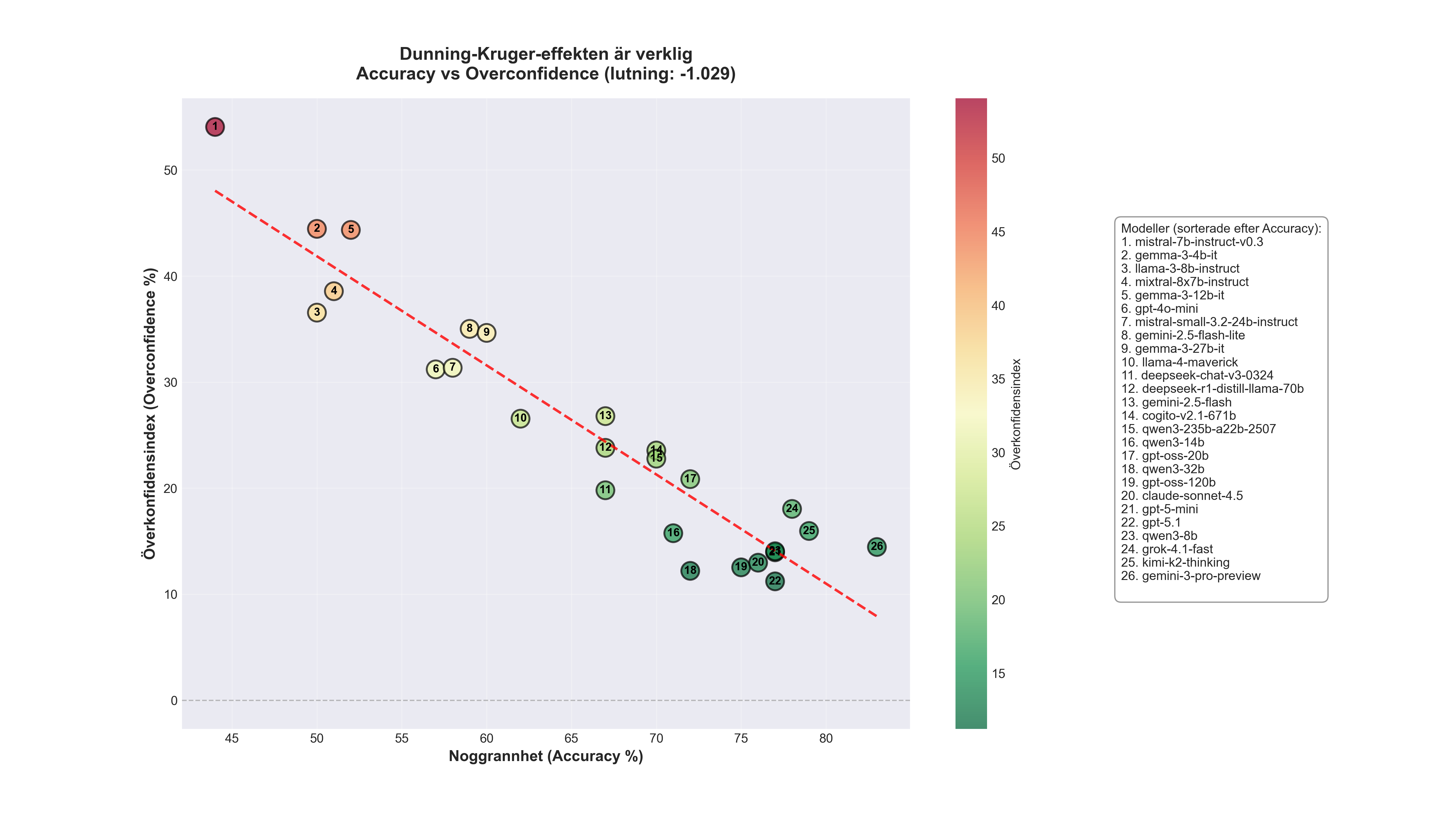
Inte en enda modell underskattar sig själv. Skillnaderna är dock enorma.
| Modell | Rätt | Noggrannhet | Säkerhet | Överkonfidens |
|---|---|---|---|---|
| Gemini 3 Pro | 83/100 | 83,0% | 97,5% | +14,5% |
| Kimi K2 Thinking | 79/100 | 79,0% | 95,0% | +16,0% |
| Grok 4.1 Fast | 78/100 | 78,0% | 96,0% | +18,0% |
| Qwen3 8B | 77/100 | 77,0% | 91,0% | +14,0% |
| GPT-5.1 | 77/100 | 77,0% | 88,2% | +11,2% |
| GPT-5 Mini | 77/100 | 77,0% | 91,0% | +14,0% |
| Claude Sonnet 4.5 | 76/100 | 76,0% | 89,0% | +13,0% |
| GPT OSS 120B | 75/100 | 75,0% | 87,5% | +12,5% |
| GPT OSS 20B | 72/100 | 72,0% | 92,8% | +20,8% |
| Qwen3 32B | 72/100 | 72,0% | 84,2% | +12,2% |
| Qwen3 14B | 71/100 | 71,0% | 86,8% | +15,8% |
| DeepCogito v2.1 671B | 70/100 | 70,0% | 93,5% | +23,5% |
| Qwen3 235B | 70/100 | 70,0% | 92,8% | +22,8% |
| DeepSeek Chat v3 | 67/100 | 67,0% | 86,8% | +19,8% |
| DeepSeek R1 Distill 70B | 67/100 | 67,0% | 90,8% | +23,8% |
| Gemini 2.5 Flash | 67/100 | 67,0% | 93,8% | +26,8% |
| Llama 4 Maverick | 62/100 | 62,0% | 88,5% | +26,5% |
| Gemma 3 27B | 60/100 | 60,0% | 94,6% | +34,6% |
| Gemini 2.5 Flash Lite | 59/100 | 59,0% | 94,0% | +35,0% |
| Mistral Small 24B | 58/100 | 58,0% | 89,3% | +31,4% |
| GPT-4o Mini | 57/100 | 57,0% | 88,2% | +31,2% |
| Gemma 3 12B | 52/100 | 52,0% | 96,3% | +44,3% |
| Mixtral 8x7B | 51/100 | 51,0% | 89,6% | +38,6% |
| Gemma 3 4B | 50/100 | 50,0% | 94,5% | +44,5% |
| Llama 3 8B | 50/100 | 50,0% | 86,5% | +36,5% |
| Mistral 7B v0.3 | 44/100 | 44,0% | 98,1% | +54,1% |
Mistral 7B har 44% rätt men påstår sig vara 98% säker, en överskattning med över 54 procentenheter. GPT-5.1 har 77% rätt och rapporterar 88% säkerhet. Fortfarande överkonfident med 11 procentenheter, men betydligt mer realistisk.
Resultat 2: Dunning-Kruger i praktiken
För att tydligare se mönstret delade jag upp modellerna i fyra grupper (kvartiler) baserat på deras faktiska noggrannhet:
| Grupp | Antal | Medel noggrannhet | Medel säkerhet | Medel överkonfidens |
|---|---|---|---|---|
| Grupp 1 (sämsta kvartilen) | 6 | 50,7% | 92,2% | +41,5% |
| Grupp 2 | 6 | 62,2% | 90,7% | +28,5% |
| Grupp 3 | 6 | 70,3% | 90,7% | +20,3% |
| Grupp 4 (bästa kvartilen) | 8 | 77,8% | 91,9% | +14,1% |
Mönstret är kristallklart. De svagaste modellerna (Grupp 1) har i snitt 51% rätt, knappt bättre än slump, men rapporterar 92% säkerhet. Överskattningen ligger på 41,5 procentenheter. De starkaste modellerna (Grupp 4) har 78% rätt och rapporterar 92% säkerhet, en överskattning på "bara" 14,1 procentenheter.
Noterbart: de starka modellerna underskattar sig inte heller (vilket ibland händer hos mänskliga experter). De är bara betydligt mer realistiska i sin självbild. Alla fyra grupper rapporterar nästan identisk genomsnittlig säkerhet (90 till 92%), men den faktiska kompetensen varierar enormt.
Resultat 3: Danger Zone, när självsäkerhet blir farligt
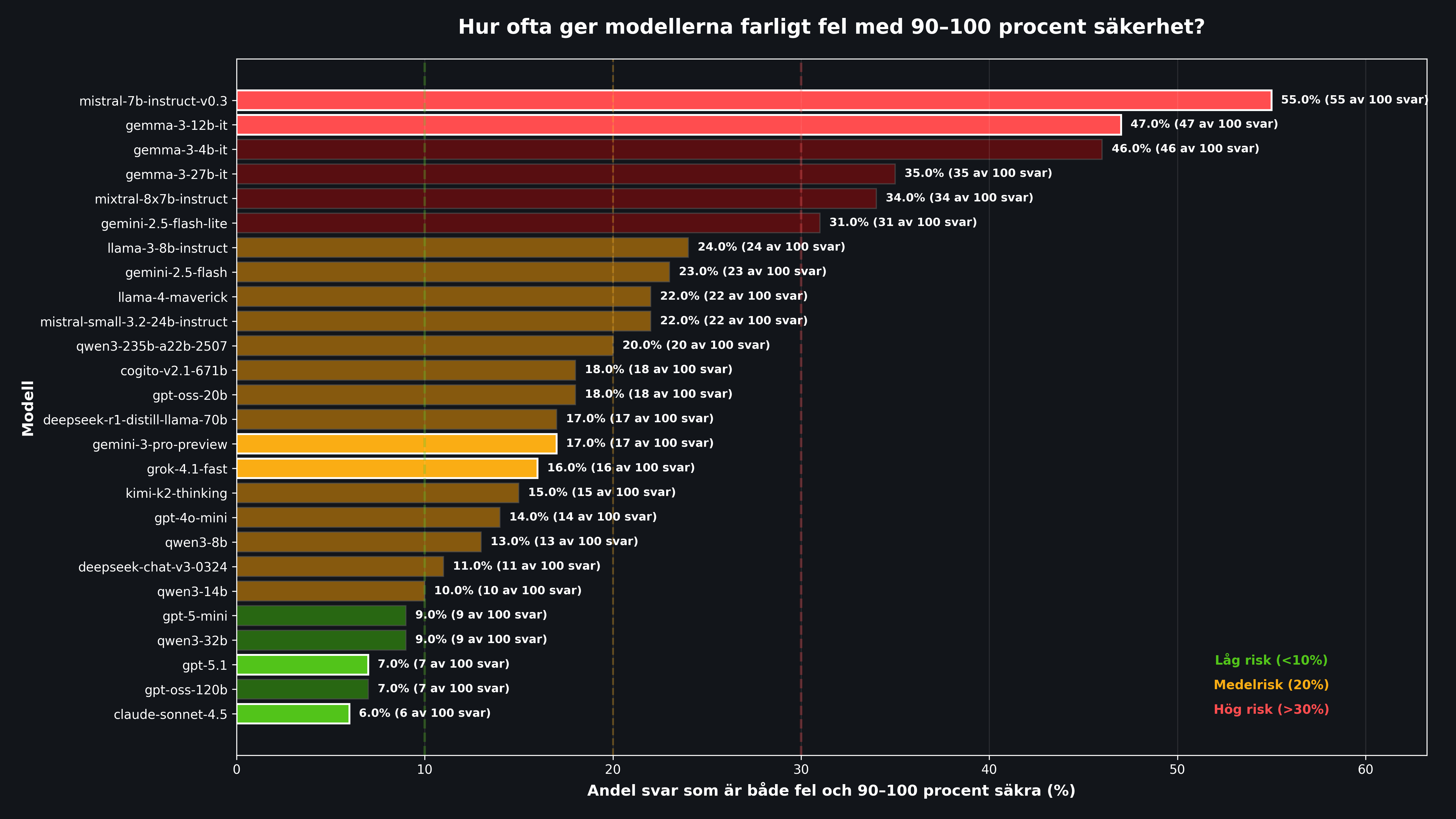
En sak är att vara lite för självsäker i genomsnitt. Men det verkliga problemet uppstår när en modell är extremt säker på fel information. Det är då vi som användare riskerar att lita blint på felaktig information.
| Grupp | H/N | E/H | E/Tot Fel | E/N |
|---|---|---|---|---|
| Grupp 1 (sämsta) | 77,0% | 47,1% | 73,0% | 36,7% |
| Grupp 2 | 74,3% | 30,2% | 59,7% | 23,0% |
| Grupp 3 | 78,3% | 20,5% | 54,5% | 16,3% |
| Grupp 4 (bästa) | 81,1% | 13,4% | 52,9% | 11,2% |
De svaga modellerna angav 90 till 100% säkerhet på 77% av alla svar, och av dessa var hela 47% fel. Det ger 36,7% farliga fel totalt. Tre gånger värre än de bästa modellerna (11,2%).
Även för toppmodellerna sker dock över hälften av alla misstag med hög självsäkerhet (E/Tot Fel 52,9%). Det innebär att det är svårt att använda "säkerhetsnivån" som en pålitlig varningssignal, även hos de bästa modellerna.
Resultat 4: Enskilda modeller i detalj
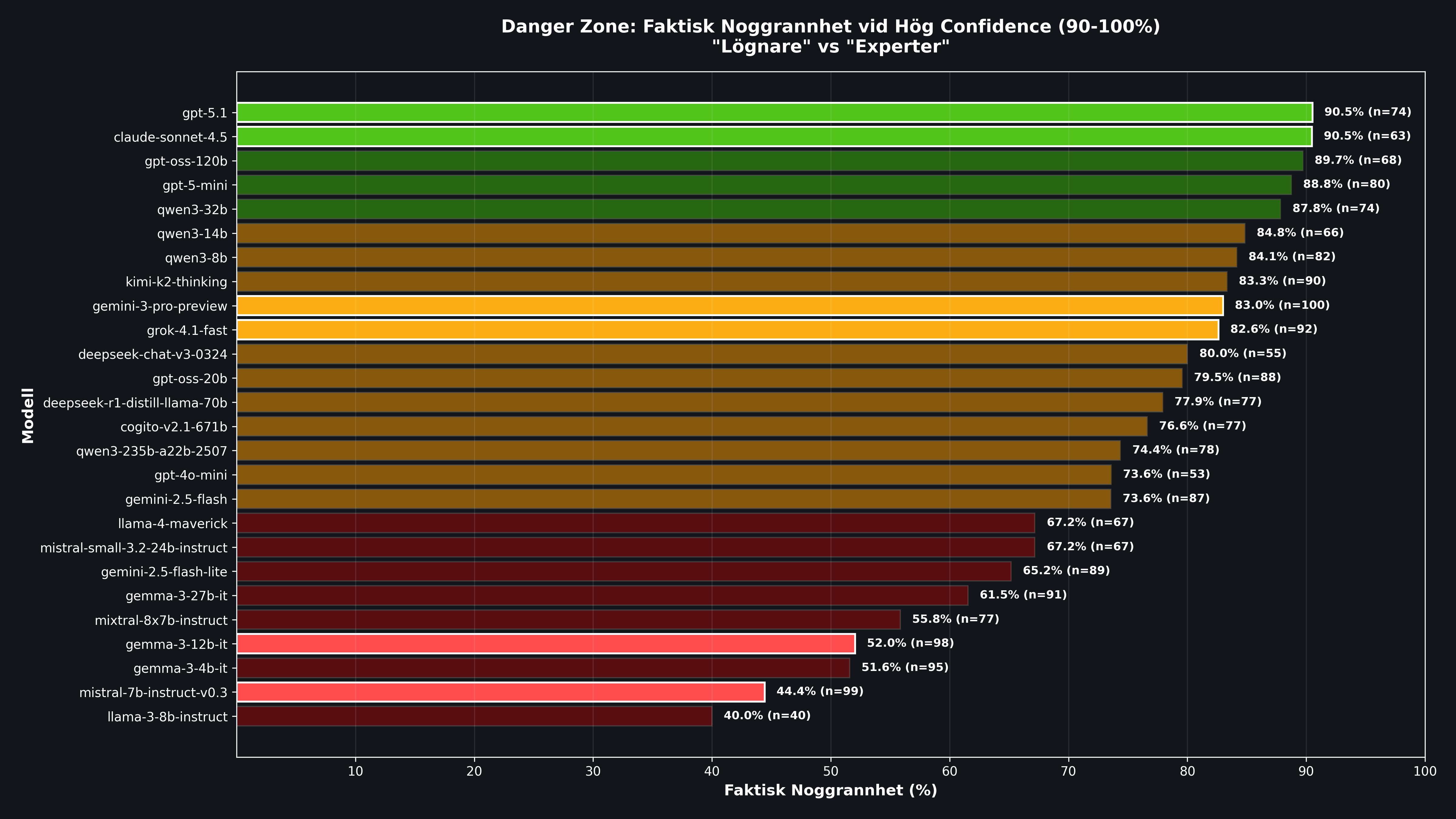
| Modell | H/N | E/H | E/N (±SE) | Notering |
|---|---|---|---|---|
| Mistral 7B v0.3 | 99,0% | 55,6% | 55,0% ±5,0% | Sämst av alla. 55 av 100 svar är farliga fel. |
| Gemma 3 12B | 98,0% | 48,0% | 47,0% ±5,0% | Nästan hälften av alla svar felaktiga + självsäkra. |
| Gemma 3 4B | 95,0% | 48,4% | 46,0% ±5,0% | Liten modell, maximal självöverskattning. |
| Gemini 3 Pro | 100,0% | 17,0% | 17,0% ±3,8% | 100% av svaren i Danger Zone. Säkerheten är värdelös som signal. |
| GPT-5.1 | 74,0% | 9,5% | 7,0% ±2,6% | Bland de mest pålitliga. Låg andel farliga fel. |
| Claude Sonnet 4.5 | 63,0% | 9,5% | 6,0% ±2,4% | Lägst E/N av alla. Bäst kalibrerad. |
Gemini 3 Pro är ett särskilt intressant fall. Den hade högst faktisk noggrannhet (83/100) men angav 90 till 100% säkerhet på varje enskilt svar. Det innebär att alla dess 17 fel levererades med maximal självsäkerhet. Säkerhetsnivån ger dig alltså ingen som helst hjälp att avgöra när du bör vara extra kritisk.
Mistral 7B representerar det värsta scenariot: 44% rätt, 98% genomsnittlig säkerhet, 55% farliga fel. Det är textboksdefinitionen av Dunning-Kruger i AI-form: extremt låg kompetens kombinerat med maximal självsäkerhet.
Claude Sonnet 4.5 och GPT-5.1 sticker ut som de säkraste valen med E/N på 6 till 7%. De är inte perfekta men har den bästa kalibreringen mellan självsäkerhet och faktisk förmåga.
Noterbart: storlek hjälper, men är inte allt
Tre trendlinjer beräknades:
- Accuracy vs Overconfidence (lutning: −1,029): För varje procentenhet högre noggrannhet, sjunker överskattningen med cirka 1 procentenhet. Tydligt negativt samband.
- Size vs Accuracy (lutning: +7,23): Större modeller presterar generellt bättre, men sambandet är inte perfekt. Qwen3 8B (77%) slår många modeller som är 10x större.
- Size vs Overconfidence (lutning: −7,85): Större modeller är generellt bättre kalibrerade, men med stora avvikelser.
Slutsatsen: storlek hjälper, men träningsmetod, data och arkitektur spelar minst lika stor roll. En vältränad 8B modell kan prestera bättre än modeller som är 10 gånger större.
Metodik
- API: OpenRouter
- Temperatur: 0,0 (deterministisk)
- Svarsformat: JSON med svar och säkerhetsprocent (0 till 100)
- Modeller: 26 stycken, från 4B till 671B parametrar
- Antal frågor: 100 per modell
- Totalt: 2 600 svar
- Frågekategorier: Ja/Nej, flerval, kortsvar, olympiadmatematik
- Statistisk signifikans: Standardfel (SE) beräknat, 95% konfidensintervall
Slutsats
Språkmodeller lider av Dunning-Kruger-effekten, och det har praktiska konsekvenser.
1. Överkonfidens är universell. Inte en enda av 26 modeller underskattar sig själv. Alla rapporterar högre säkerhet än vad deras faktiska noggrannhet motiverar. Skillnaden sträcker sig från +11% (GPT-5.1) till +54% (Mistral 7B).
2. De svagaste modellerna överskattar sig mest. Grupp 1 (sämsta kvartilen) har 51% rätt men 92% säkerhet. En överskattning på 41 procentenheter. Det är exakt det mönster Dunning och Kruger beskrev hos människor: de som vet minst tror sig veta mest.
3. Danger Zone är verklig. Mellan 6% och 55% av alla svar levereras som både felaktiga och med extrem självsäkerhet. För svaga modeller är det över en tredjedel av alla svar. Det innebär att du inte kan använda modellens uttalade säkerhet som en pålitlig signal för korrekthet.
4. Ingen modell är immun. Även hos toppmodellerna sker över hälften av alla misstag med hög självsäkerhet. Blind tillit är aldrig motiverad, oavsett vilken modell du använder.
I praktiken innebär det här att du bör behandla modellens uttalade säkerhet med stor skepsis. Om du bygger system som förlitar sig på AI, designa med felmarginaler: flera oberoende kontroller, mänsklig granskning för kritiska beslut, och framförallt en medvetenhet om att "jag är 95% säker" från en språkmodell inte betyder samma sak som 95% sannolikhet att svaret är korrekt.