AI vs Högskoleprovet: Hur klarade 17 små språkmodeller den verbala delen?
Publicerad 2 maj 2025 av Joel Thyberg

Test av Små Språkmodellers Svenska Språkförståelse via Ollama
Den här texten (och den tillhörande videon på YouTube) presenterar en undersökning av hur väl olika små språkmodeller, tillgängliga via Ollama, förstår det svenska språket. Det är särskilt intressant att undersöka just mindre modeller eftersom de ofta kan köras lokalt, även utan tillgång till mycket kraftfull datorkraft. Detta medför flera viktiga fördelar: dels möjligheten att använda modellerna helt offline, dels en avsevärt förhöjd datasäkerhet. När modellerna körs lokalt behöver ingen information som bearbetas lämna användarens egen dator, vilket eliminerar risken för att det man skriver sprids externt.
Metod för Testet
För att genomföra detta test har 17 olika språkmodeller, tillgängliga via Ollama, laddats ned och testats. Dessa modeller kunde köras lokalt och hade parametrar som varierade från 3 till 8 miljarder, samt filstorlekar på mellan 2 och 5 GB.
En lokal chattfunktion byggdes upp för att kunna interagera med varje enskild modell.

Därefter ställdes samma uppsättning frågor till varje modell. Frågorna hämtades från den verbala delen av ett nyligen genomfört högskoleprov (specifikt 30 frågor från Provpass 4, Högskoleprovet våren 2024). Den verbala delen av högskoleprovet består vanligtvis av 40 frågor:
- 10 frågor om ordförståelse
- 10 frågor om svensk läsförståelse
- 10 frågor om meningskomplettering
- 10 frågor om engelsk läsförståelse
Eftersom detta test specifikt inriktade sig på modellernas svenska språkförståelse, uteslöts de tio frågorna som avsåg engelsk läsförståelse. Varje modell fick därmed besvara totalt 30 svenska verbala frågor, med ett svarsförsök per fråga.
Resultat
När alla modeller hade svarat på de 30 frågorna sammanställdes resultaten, vilket ni kan se nedan.
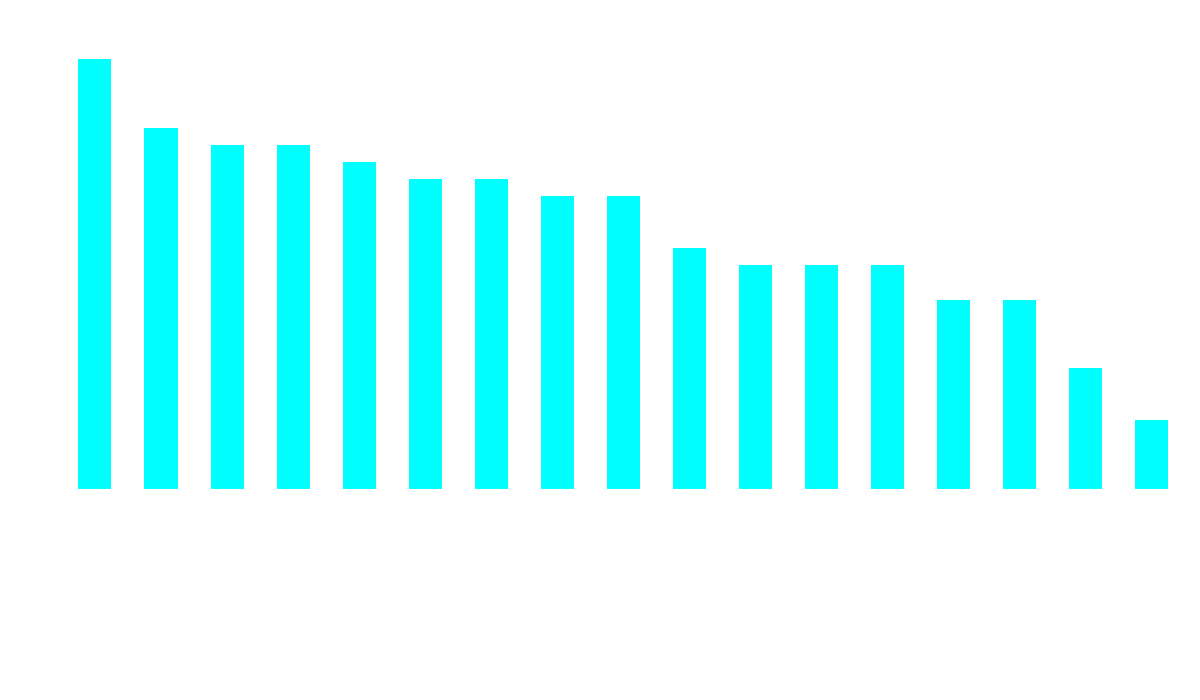 Figur 1: Diagrammet redovisar det totala antalet korrekta svar (på y-axeln) per testad modell (längs x-axeln).
Figur 1: Diagrammet redovisar det totala antalet korrekta svar (på y-axeln) per testad modell (längs x-axeln).
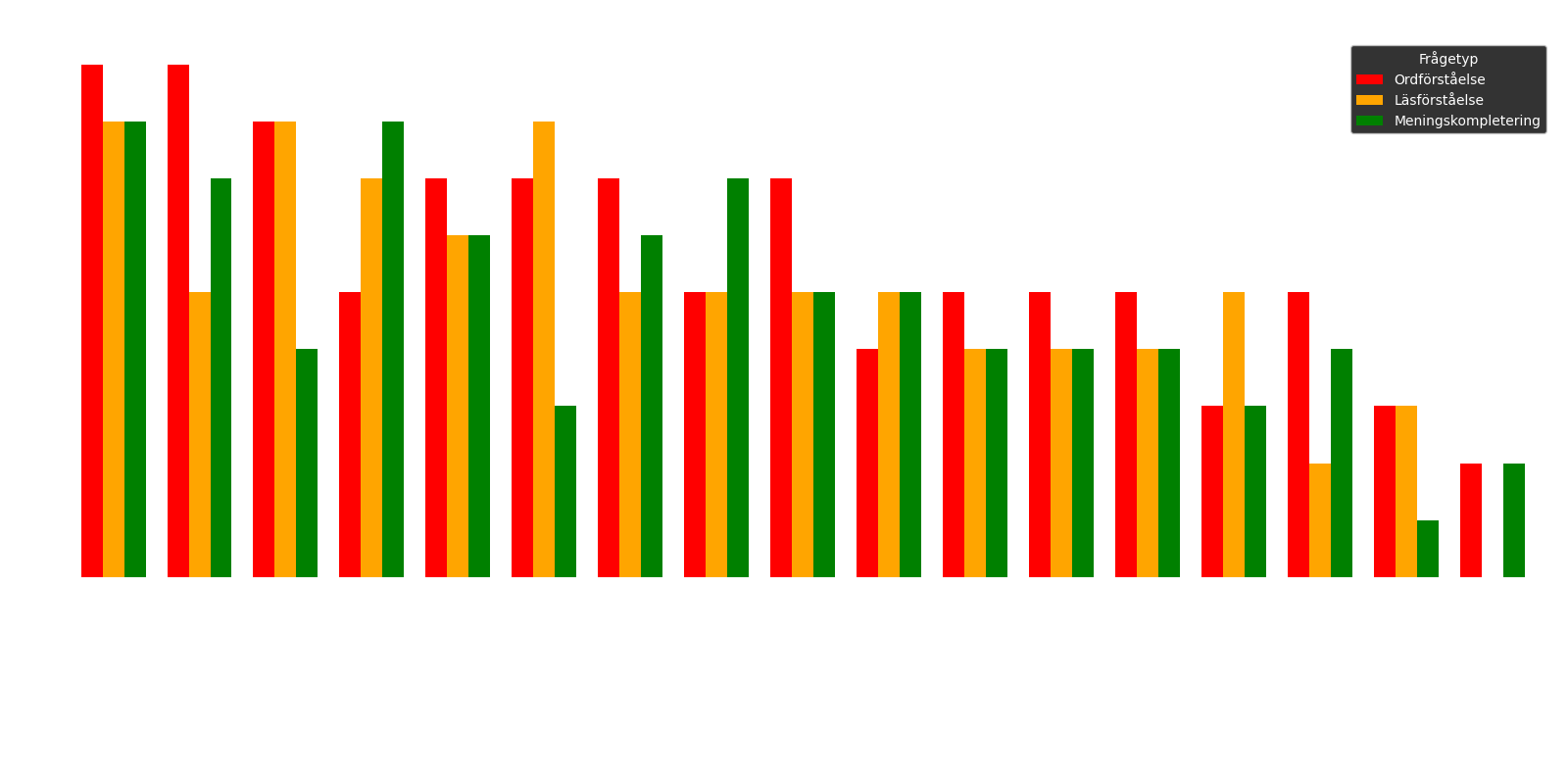 Figur 2: Diagrammet specificerar antalet korrekta svar för varje delmoment: den röda stapeln representerar ordförståelse, den orangea läsförståelse och den gröna meningskomplettering.
Figur 2: Diagrammet specificerar antalet korrekta svar för varje delmoment: den röda stapeln representerar ordförståelse, den orangea läsförståelse och den gröna meningskomplettering.
Resultaten visar tydligt att modellen qwen2:7b presterade bäst, med 25 korrekta svar av 30 möjliga. Denna modell följs av gemma:9b, som uppnådde 21 av 30 korrekta svar. Därefter delar command-r:35b och deepseek-coder-v2:16b på tredjeplatsen, båda med 20 rätt.
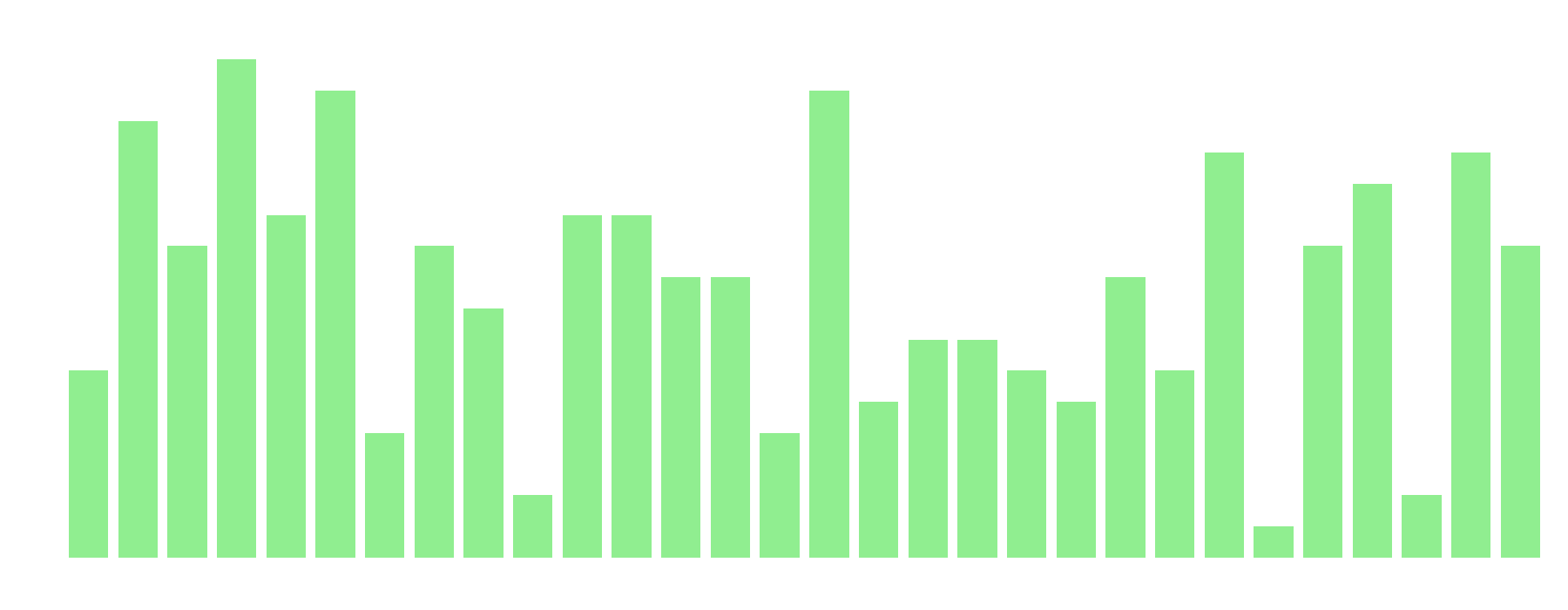 Figur 3: Diagrammet visar antalet modeller med korrekta svar på y-axeln och frågenummer på x-axeln.
Figur 3: Diagrammet visar antalet modeller med korrekta svar på y-axeln och frågenummer på x-axeln.
Av diagrammen ovan kan vi se att fråga 4 var den lättaste för modellerna, medan fråga 25 var den svåraste.
Fråga 4 (Lättast): Välj det alternativ (A-E) som bäst motsvarar betydelsen av ordet "intervention".
- A. avbrott
- B. stödfunktion
- C. ingripande (Rätt svar)
- D. förmedling
- E. inaktivitet
Fråga 25 (Svårast): Välj det alternativ (A-D) som bäst passar in på platsen markerad med X i meningen/meningarna.
"Det som oroar forskarna är inte att höghastighetstågen kommer att få järnvägsbroarna att rasa, utan snarare att broarna inte kan trafikeras i så höga hastigheter med X spårstabilitet. Dessutom lär kostnaden för underhåll X om spåren på broarna måste justeras var och varannan vecka."
- A. beräknad – komma till korta
- B. likartad – mana till eftertanke
- C. tillförlitlig – tas i anspråk
- D. bibehållen – skjuta i höjden (Rätt svar)
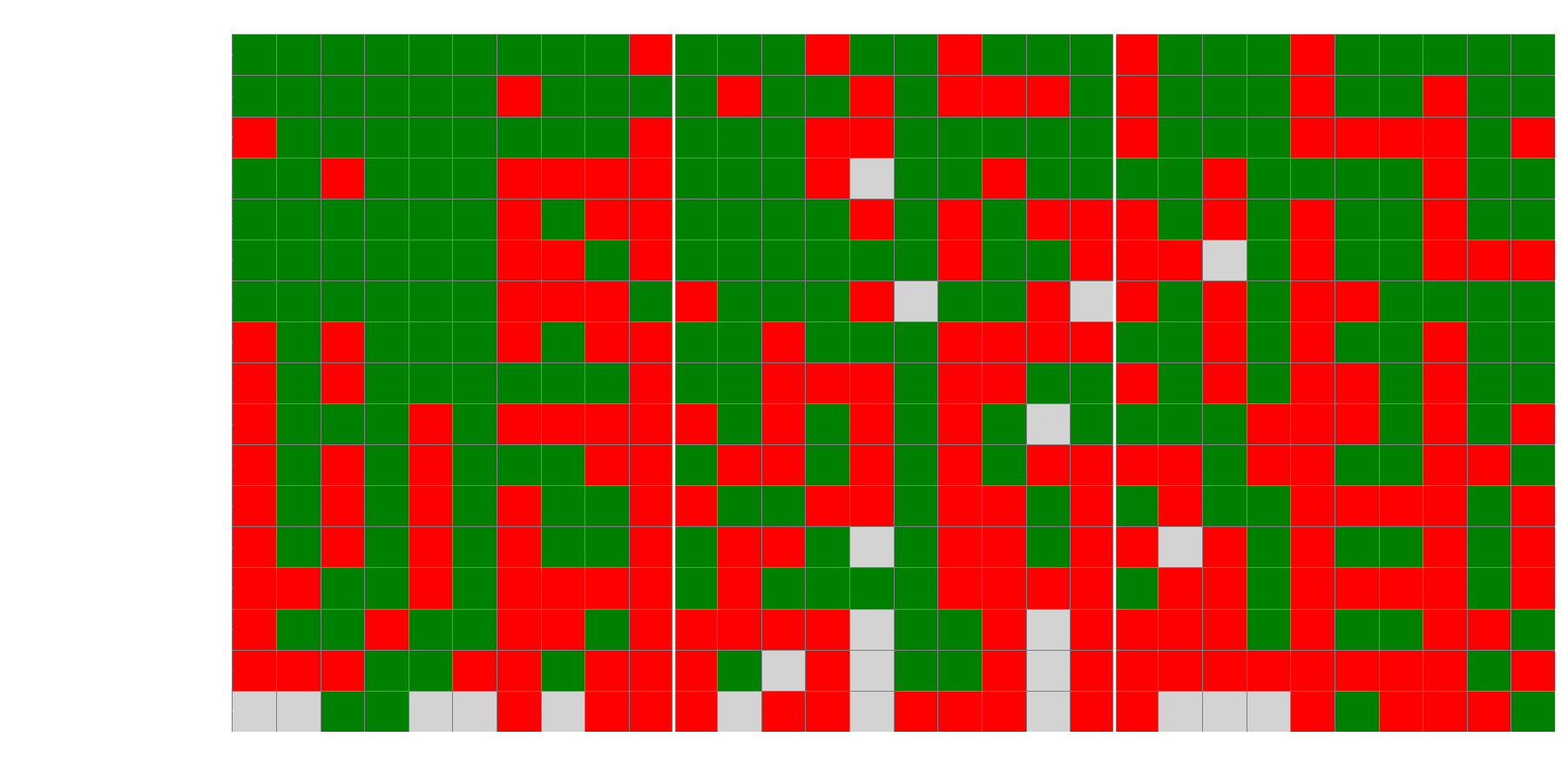 Figur 4: Diagrammet visar en heat map över ifall modellerna svarade rätt (grön ruta), fel (röd ruta) eller inget vettigt alls (grå ruta) på de olika frågorna.
Figur 4: Diagrammet visar en heat map över ifall modellerna svarade rätt (grön ruta), fel (röd ruta) eller inget vettigt alls (grå ruta) på de olika frågorna.
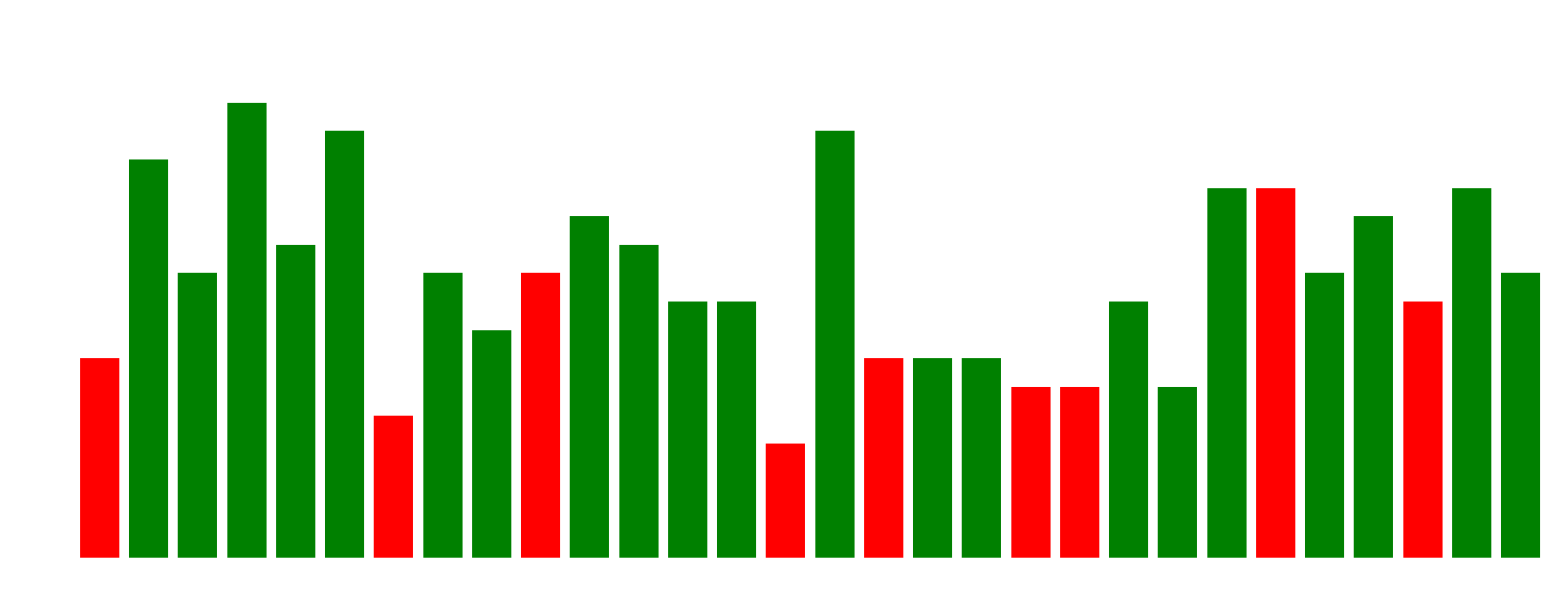 Figur 5: Diagrammet visar det vanligaste svaret för varje fråga, och om det vanligaste svaret var korrekt (grön stapel) eller felaktigt (röd stapel).
Figur 5: Diagrammet visar det vanligaste svaret för varje fråga, och om det vanligaste svaret var korrekt (grön stapel) eller felaktigt (röd stapel).
En intressant iakttagelse från Figur 4 och 5 är hur modellerna tenderar att agera när de svarar fel. Heatmapen (Figur 4) visar att vissa frågor var genomgående svåra för nästan alla modeller. När vi sedan tittar på de vanligaste svaren (Figur 5), ser vi att för många av dessa svåra frågor väljer majoriteten av modellerna samma felaktiga svarsalternativ. Detta indikerar en anmärkningsvärd enhetlighet i deras "missförstånd", vilket antyder att de kan ha liknande brister eller förutfattade meningar som leder dem till samma felaktiga slutsats.
Tidsanalys
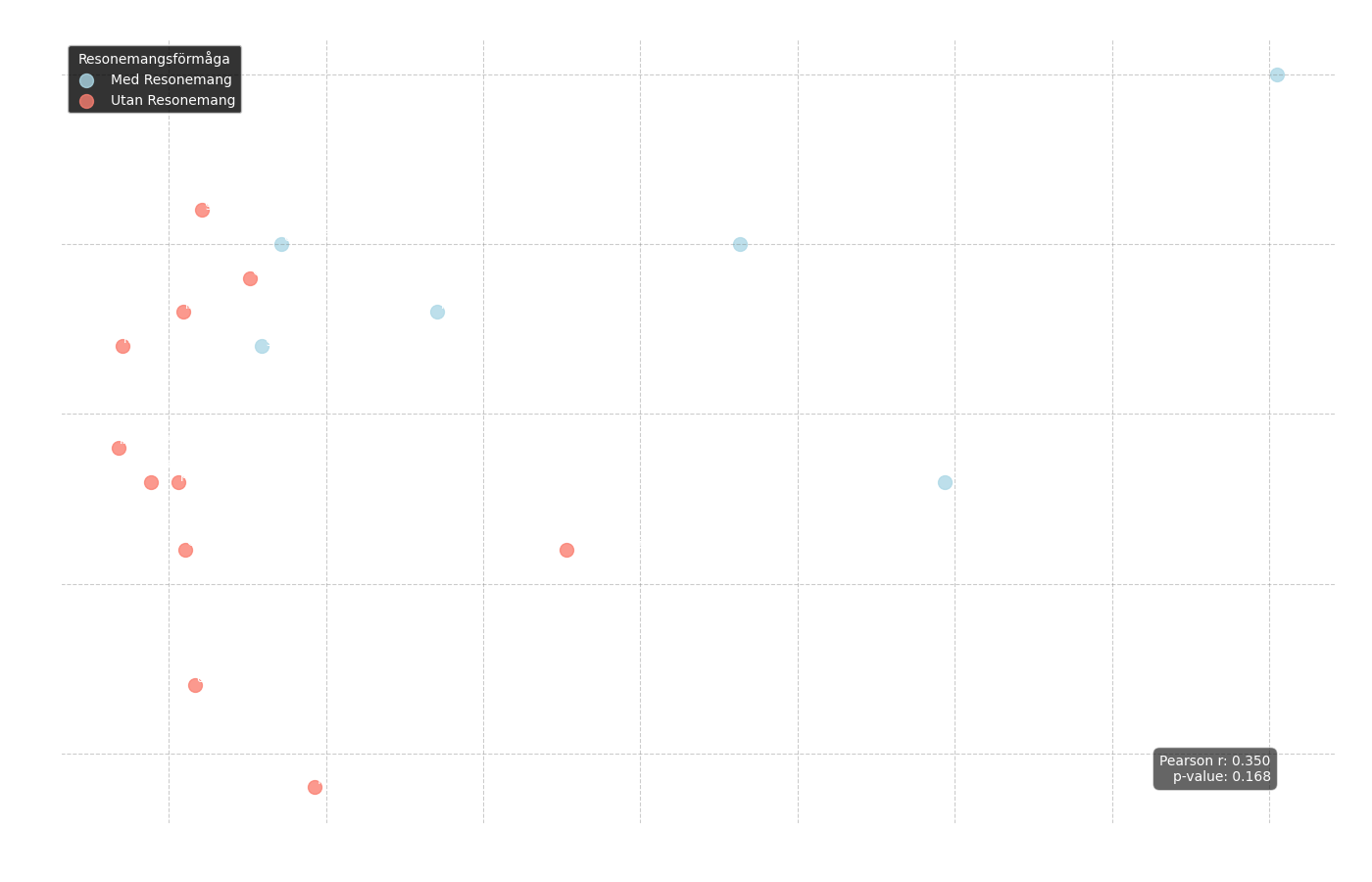 Figur 6: Scatterplott som visar sambandet mellan korrekta svar (y-axeln) och medelsvarstid (x-axeln). Blå punkter representerar "resonerande" modeller och röda punkter representerar standardmodeller.
Figur 6: Scatterplott som visar sambandet mellan korrekta svar (y-axeln) och medelsvarstid (x-axeln). Blå punkter representerar "resonerande" modeller och röda punkter representerar standardmodeller.
Från detta diagram kan vi först analysera den övergripande korrelationen mellan svarstid och antal korrekta svar:
Pearson r = 0.350
p-värde = 0.168
Resultatet är inte statistiskt signifikant, vilket innebär att en snabbare modell inte nödvändigtvis var bättre eller sämre. Däremot kan vi tydligt se i diagrammet att de blå punkterna, som representerar modeller med resonemangsförmåga, tenderar att ha en betydligt längre genomsnittlig svarstid.
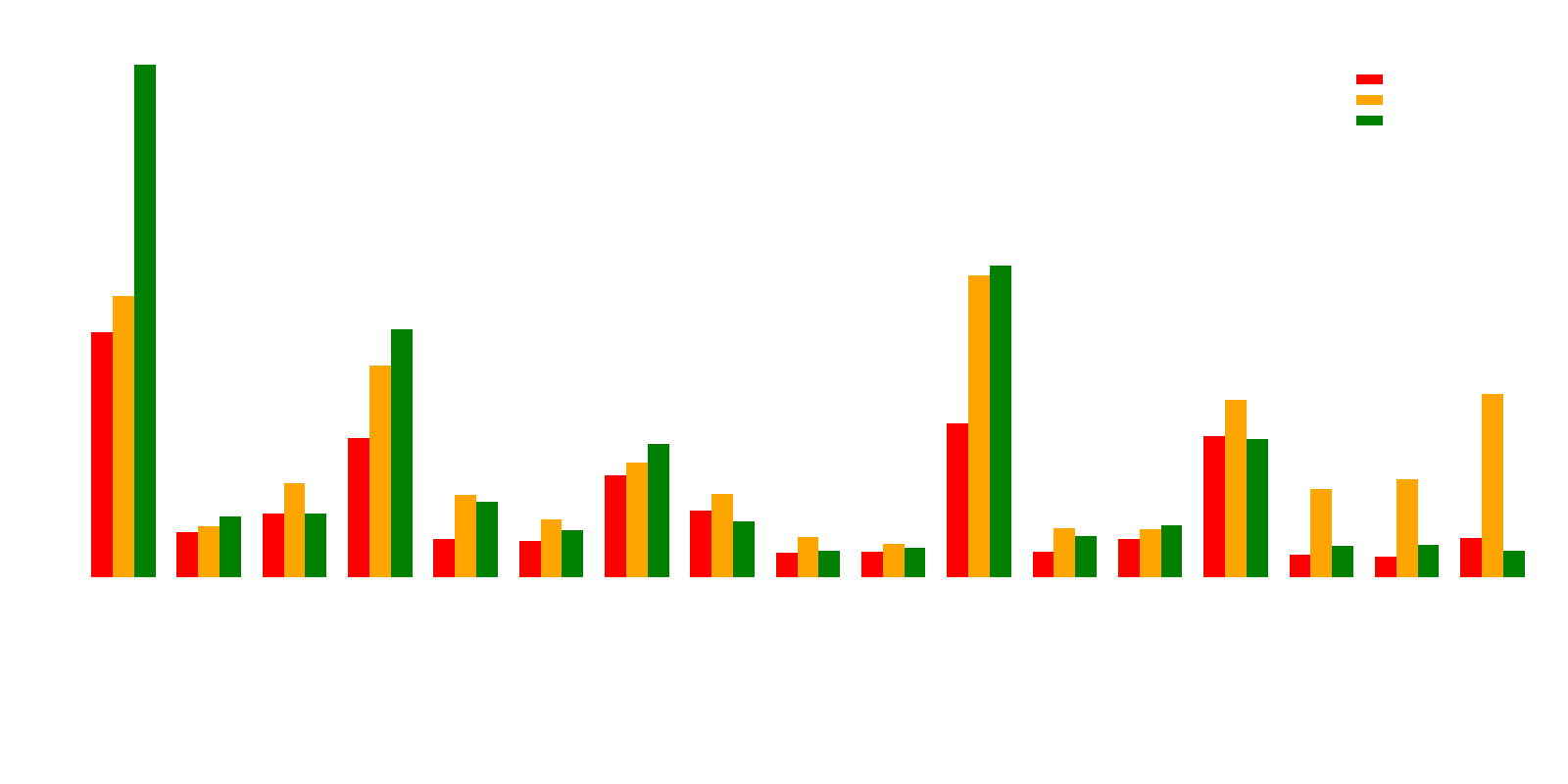 Figur 7: Diagram som visar medelsvarstid per frågetyp för varje enskild modell.
Figur 7: Diagram som visar medelsvarstid per frågetyp för varje enskild modell.
Detta blir ännu tydligare i Figur 7. Här ser vi att testets vinnare, qwen3:8b – som är en resonerande modell (och därmed en blå prick i Figur 6) – också är en av de modeller som genomgående tar längst tid på sig att svara. Detta understryker att mer kapabla modeller kan behöva mer "betänketid" för att leverera svar av högre kvalitet.
Slutligen kunde ett annat intressant tidssamband observeras: frågor som generellt tog längre tid för modellerna att besvara hade en högre andel felaktiga svar.
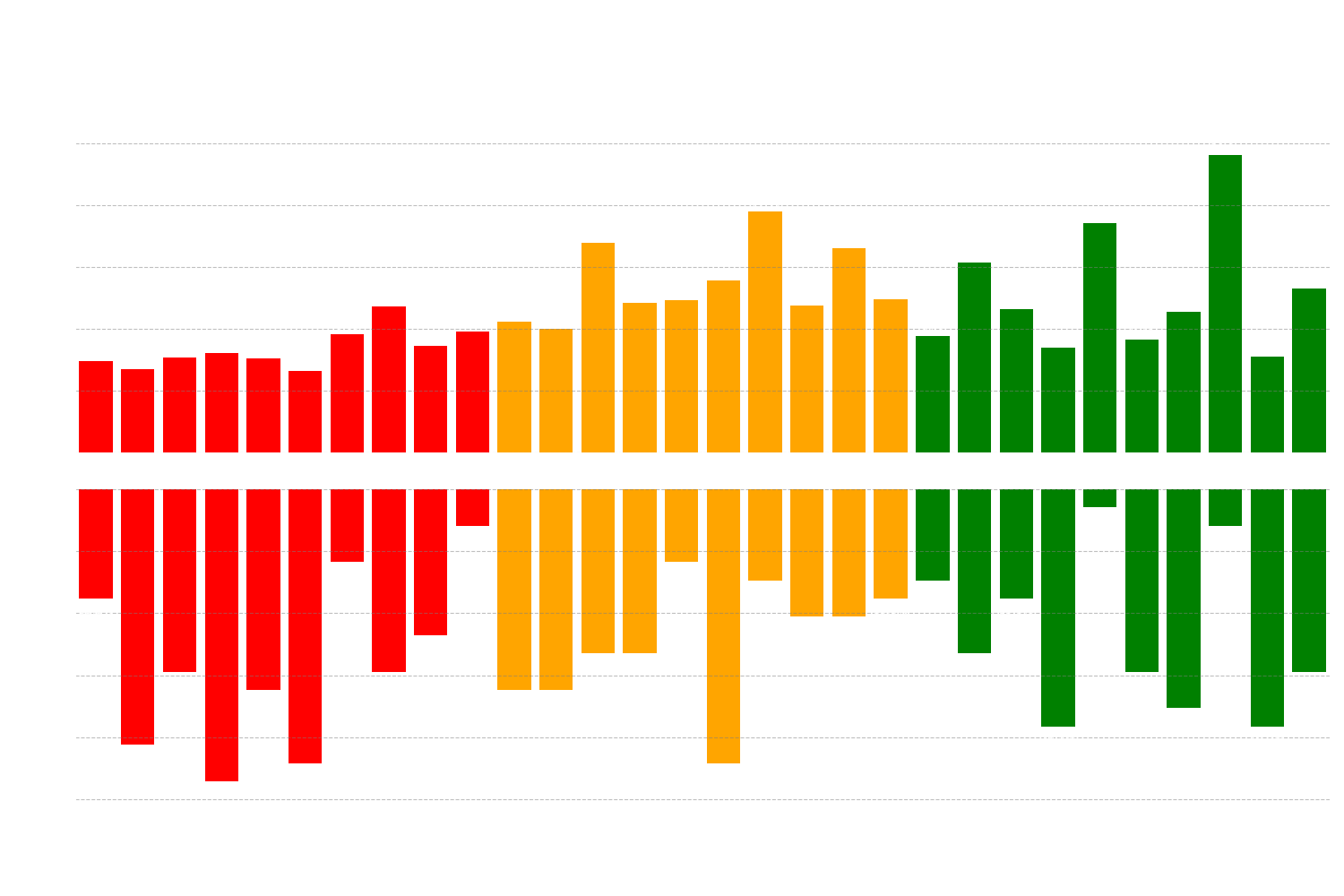 Figur 8: Diagram som visar korrelationen mellan andelen korrekta svar och den genomsnittliga svarstiden för varje enskild fråga.
Figur 8: Diagram som visar korrelationen mellan andelen korrekta svar och den genomsnittliga svarstiden för varje enskild fråga.
Korrelation: Svarstid vs Andel Rätt (per Fråga)
Spearman ρ = -0.487 (p = 0.006)
Pearson r = -0.515 (p = 0.004)
Här är resultatet statistiskt signifikant. Den negativa korrelationen visar ett måttligt starkt samband: ju längre genomsnittlig svarstid för en specifik fråga, desto lägre var andelen korrekta svar. Enkelt uttryckt, när modellerna "tvekade" och tog längre tid på sig, var det oftare som de svarade fel.
Analys av Samband och Korrelationer
Vi kunde även se ett gäng andra typer av samband och korrelationer mellan olika modellers prestation och deras tekniska specifikationer. Ett av de första vi undersökte var sambandet mellan en modells specificerade kontextlängd (hur mycket information den kan "minnas" samtidigt) och dess totala antal korrekta svar.
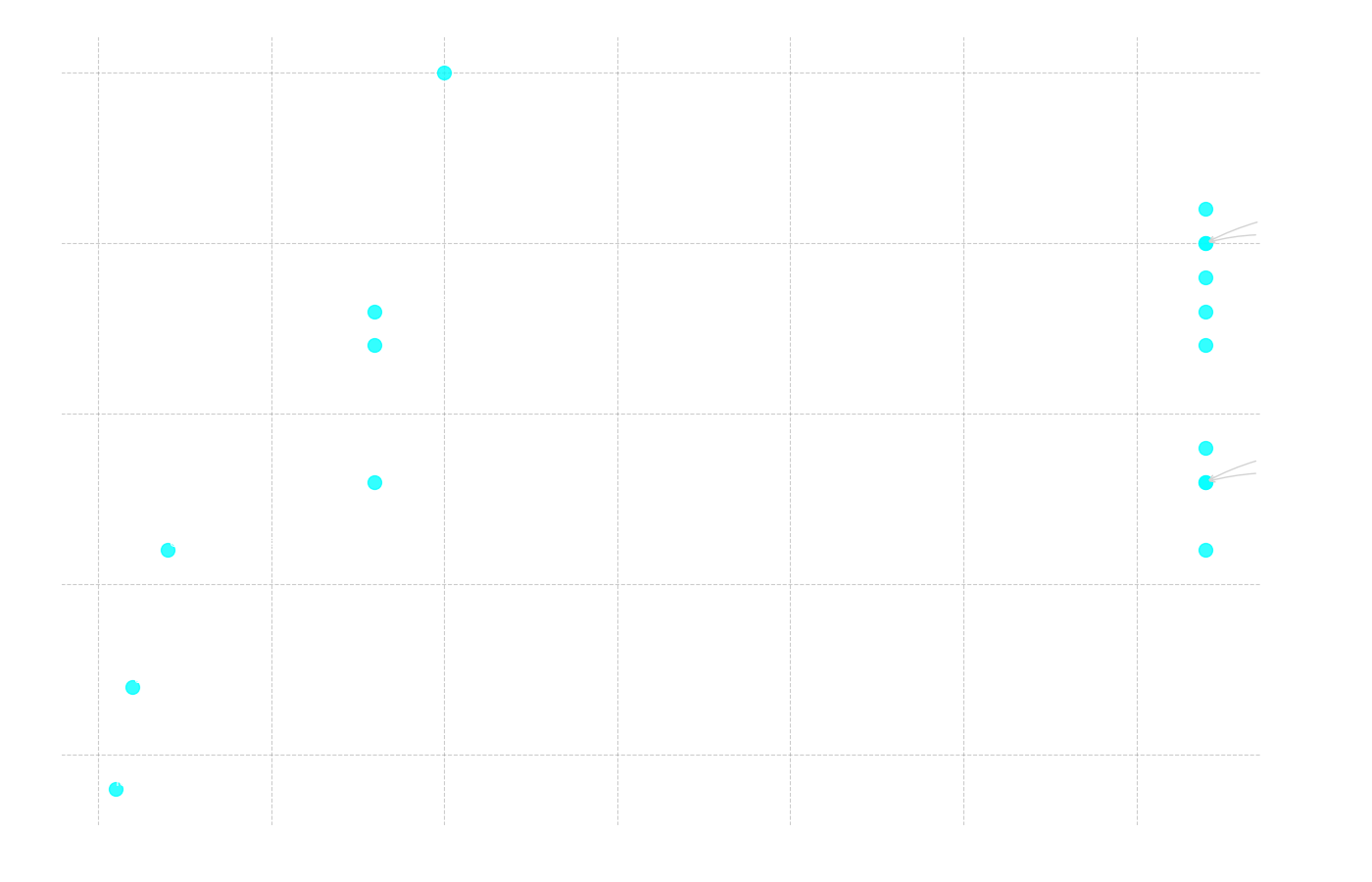 Figur 9: Scatterplott som visar sambandet mellan totalt antal korrekta svar (y-axeln) och modellens kontextlängd i tusen tokens (x-axeln).
Figur 9: Scatterplott som visar sambandet mellan totalt antal korrekta svar (y-axeln) och modellens kontextlängd i tusen tokens (x-axeln).
Korrelation: Kontextlängd vs Totalt Antal Rätt
Pearson r = 0.416 (p = 0.097)
Spearman ρ = 0.481 (p = 0.051)
Som Figur 10 illustrerar, ökade andelen felaktiga svar markant för den längsta texten. Om vi analyserar textmassorna ser vi varför. Den längsta texten (Text 2) är på 1134 ord. När denna text bearbetas genom Gemmas tokenizer omvandlas den till 2139 tokens, men för äldre modeller med andra tokenizers kan samma text generera ännu fler. Detta överstiger med råge kontextfönstret för en modell som fcole90/ai-sweden-gpt-sw3:6.7b, som endast hanterar 2000 tokens. Modellen kan alltså inte ens "se" hela frågan och texten samtidigt, vilket gör det omöjligt för den att svara korrekt.
Ett annat intressant samband att undersöka var det mellan modellernas lanseringsdatum och deras prestanda.
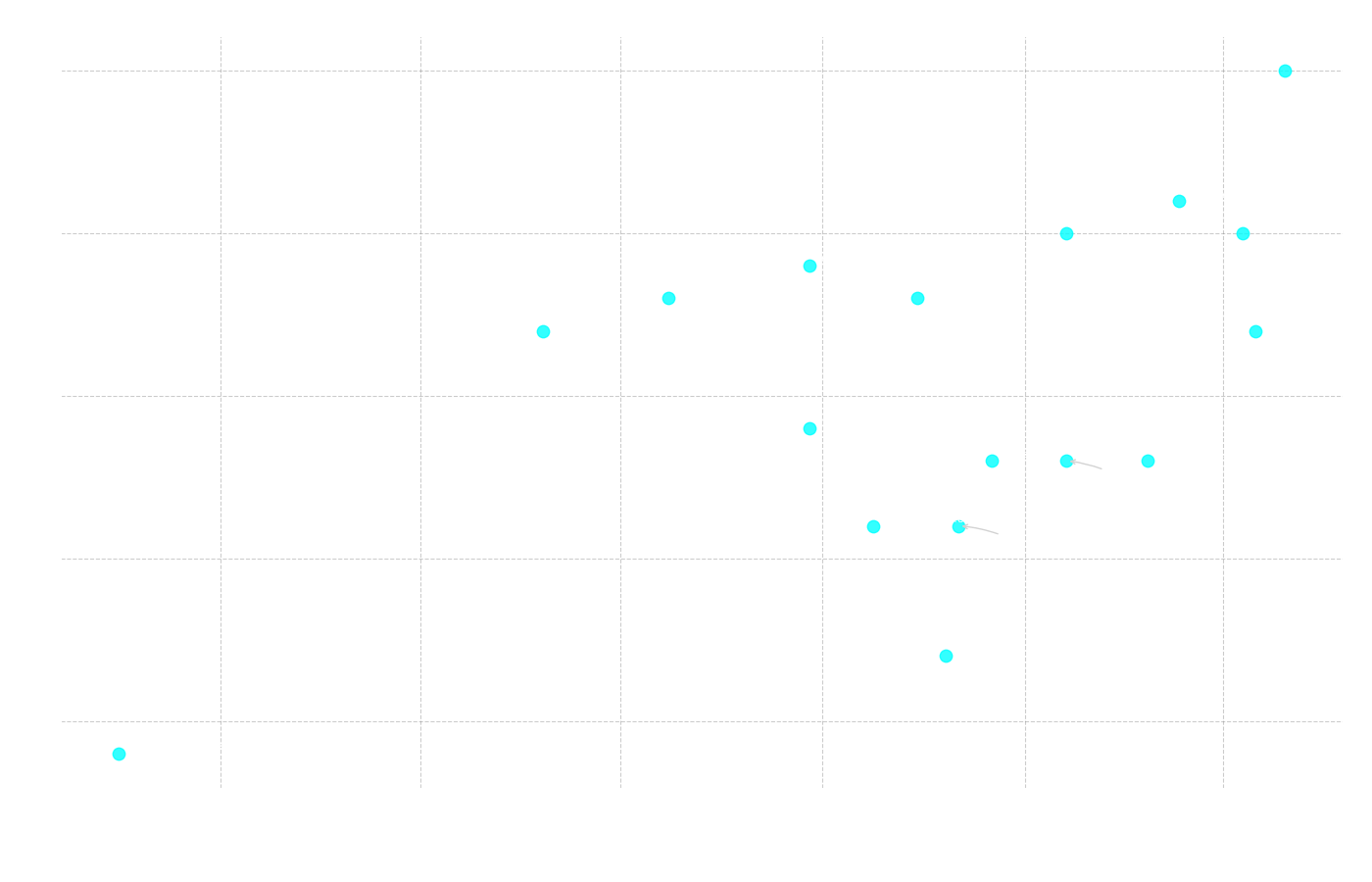 Figur 11: Scatterplott som visar sambandet mellan totalt antal korrekta svar (y-axeln) och modellens lanseringsdatum (x-axeln).
Figur 11: Scatterplott som visar sambandet mellan totalt antal korrekta svar (y-axeln) och modellens lanseringsdatum (x-axeln).
Korrelation: Lanseringsdatum vs Totalt Antal Rätt
Pearson r = 0.557 (p = 0.020)
Spearman ρ = 0.437 (p = 0.079)
Här ser vi en statistiskt signifikant positiv korrelation (Pearson r = 0.557), vilket bekräftar att nyare modeller tenderar att prestera bättre. Detta blir tydligt i Figur 11, där tre av de fyra bäst presterande modellerna också är bland de fyra senast lanserade. Samtidigt återfinns de modeller med lägst antal korrekta svar bland de som släpptes tidigast. Detta följer ett mönster som är vanligt inom all teknologi: utvecklingen går framåt. Nya modeller byggs på lärdomar från tidigare misstag och drar nytta av den senaste forskningen, vilket leder till ständigt förbättrad kapacitet.
Det avslutande sambandet vi undersökte var det mellan antalet parametrar i en modell och dess resultat.
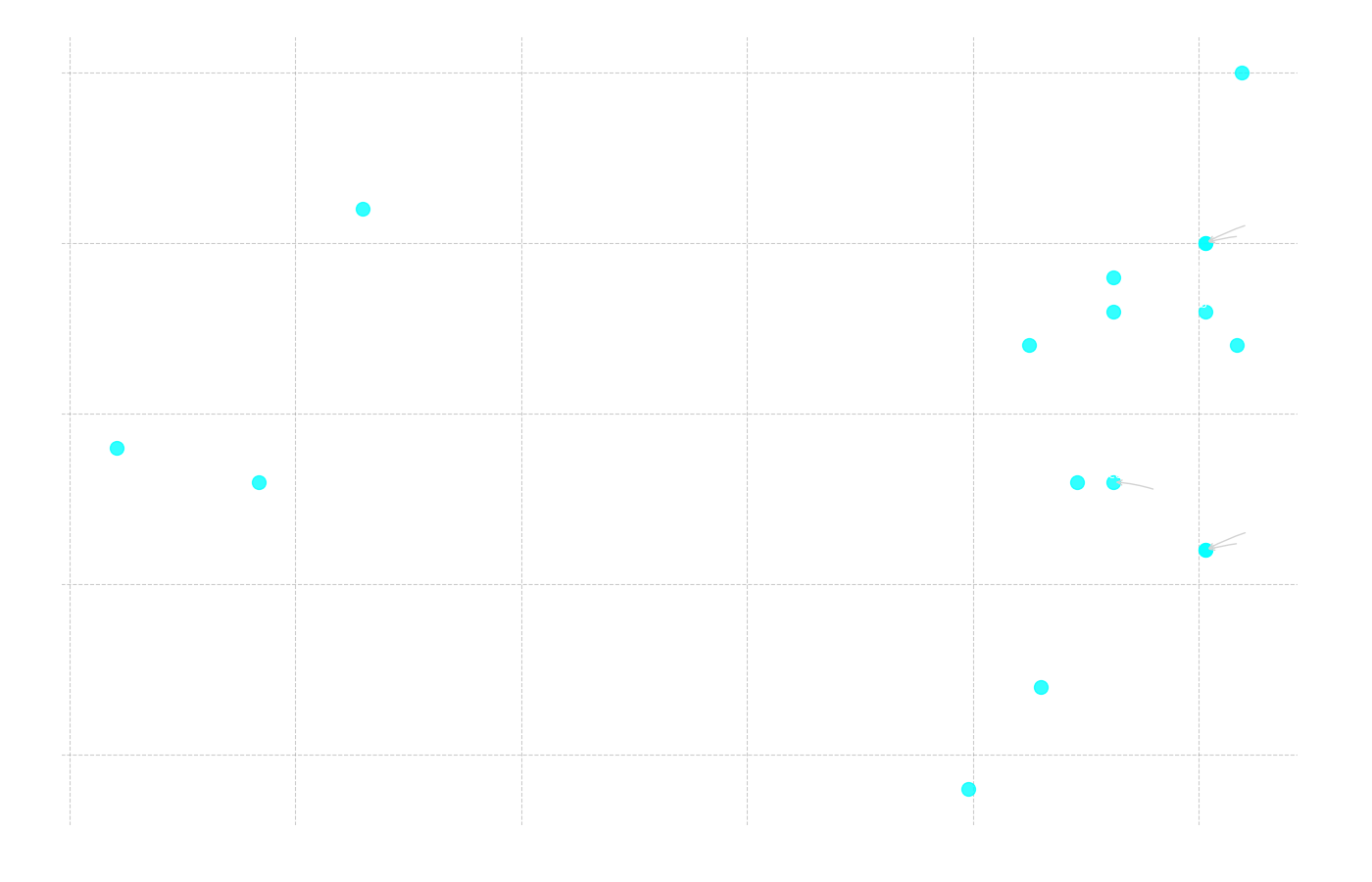 Figur 12: Scatterplott som visar sambandet mellan totalt antal korrekta svar (y-axeln) och antalet parametrar i miljarder (x-axeln).
Figur 12: Scatterplott som visar sambandet mellan totalt antal korrekta svar (y-axeln) och antalet parametrar i miljarder (x-axeln).
Korrelation: Antal Parametrar vs Totalt Antal Rätt
Pearson r = 0.099 (p = 0.706)
Spearman ρ = 0.324 (p = 0.205)
Här är korrelationen mycket svag och inte alls statistiskt signifikant, vilket är ett intressant resultat i sig. Det visar att "större är inte alltid bättre". Ett utmärkt exempel på detta är gemma3:4b, som med endast 4.3 miljarder parametrar presterade näst bäst i hela testet. Som vi sett i tidigare analyser har denna modell andra avgörande fördelar, såsom ett sent lanseringsdatum och en lång kontextlängd. Detta understryker att de tekniska förutsättningarna för att prestera väl är mer komplexa än bara ren storlek.
En Närmare Titt på Toppmodellerna
För att få en djupare förståelse för vad som skiljer de bästa modellerna åt, kan vi analysera deras prestanda per delmoment i ett radardiagram. Testets prispall bestod av qwen3:8b på första plats, gemma3:4b på andra, och en delad tredjeplats mellan cogito:8b och deepseek-r1:8b.
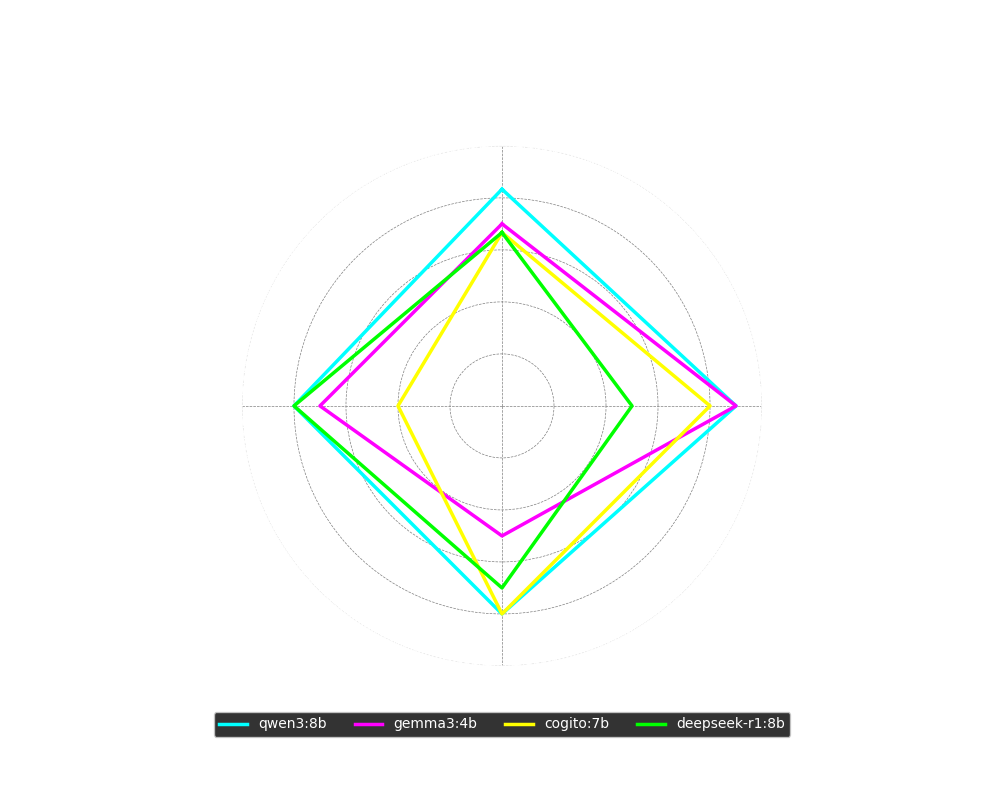 Figur 13: Radardiagram som visar procentuellt korrekta svar för de fyra toppmodellerna, uppdelat per delmoment.
Figur 13: Radardiagram som visar procentuellt korrekta svar för de fyra toppmodellerna, uppdelat per delmoment.
Av diagrammet framgår tydliga styrkor och svagheter:
- qwen3:8b var solitt och jämnt över hela linjen, med över 80% rätt på samtliga delmoment.
- gemma3:4b presterade mycket bra på ordförståelse och helt okej på meningskomplettering, men hade tydliga svårigheter med den mer krävande läsförståelsen.
- cogito:8b utmärkte sig med ett toppresultat på läsförståelse (i klass med qwen3), men presterade svagt på meningskomplettering.
- deepseek-r1:8b var, i motsats till cogito, bäst av alla på meningskomplettering men hade desto större problem med ordförståelse.
En intressant aspekt är att tre av dessa fyra modeller (qwen3, cogito, deepseek) är så kallade resonerande modeller. Detta kan förklara deras styrka i komplexa uppgifter som läsförståelse. Samtidigt kan denna förmåga ibland vara en nackdel i enklare uppgifter som ordförståelse, där en modell kan "tänka över" ett initialt korrekt svar och resonera sig fram till ett felaktigt alternativ.
Om vi ser till övriga specifikationer ser vi att qwen3:8b hade den absolut högsta medelsvarstiden i testet, tätt följd av deepseek-r1:8b på tredje högst med ca 24 sekunder. cogito:8b var betydligt snabbare med sina 9 sekunder, men alla tre utklassades av gemma3:4b som klockade in på strax över 5 sekunder. Alla fyra hade tillräckligt långa kontextfönster för testet, och alla utom gemma3:4b låg på runt 8 miljarder parametrar.
 Figur 14: En tidslinje som visar lanseringsdatum för de fyra toppmodellerna.
Figur 14: En tidslinje som visar lanseringsdatum för de fyra toppmodellerna.
Slutligen, som Figur 14 visar, lanserades alla fyra toppmodeller inom ett snävt tidsfönster under första halvan av 2025, vilket återigen bekräftar att de nyaste modellerna ofta bär på de senaste framstegen.
Se hela testet och genomgången i videon här:
Sammanfattning
Sammanfattningsvis kan man konstatera följande: För den som vill ha modellen med absolut bäst förståelse för det svenska språket är qwen3:8b det främsta valet. Om man däremot önskar en modell som svarar snabbare, är mindre och därmed kan användas på ett bredare spann av hårdvara, då framstår gemma:4b som ett mycket bra alternativ.
Resurser
- YouTube-video: AI vs Högskoleprovet
- GitHub-repo (Lokal Testapp): ollama-modelltestare
Modeller
Här är länkar till alla modeller som inkluderades i testet, sorterade efter prestanda (bäst till sämst):
- qwen3:8b (25/30)
- gemma3:4b (21/30)
- cogito:7b (20/30)
- deepseek-r1:8b (20/30)
- Qwen2.5:7b (19/30)
- llama3.1:8b (18/30)
- marco-o1:7b (18/30)
- granite3.3:8b (17/30)
- mistral:7b (17/30)
- llama3.2:3b (14/30)
- deepseek-r1:7b (13/30)
- falcon3:7b (13/30)
- phi4-mini:3.8b (13/30)
- Command-r7b:7b (11/30)
- aya-expanse:8b (11/30)
- olmo2:7b (7/30)
- fcole90/ai-sweden-gpt-sw3:6.7b (4/30)