Vad är RAG? Så svarar AI på frågor om dina dokument
Publicerad 7 maj 2025 av Joel Thyberg

Hur hittar vi information idag?
När vi vill veta något är vår första instinkt ofta att vända oss till en sökmotor. Vi formulerar en fråga och får tillbaka en lista med länkar.
 Figur 1: En klassisk Google-sökning på "Vad är RAG?".
Figur 1: En klassisk Google-sökning på "Vad är RAG?".
På senare tid har ett nytt, kraftfullt verktyg dykt upp: stora språkmodeller som ChatGPT. Istället för en lista med länkar kan vi få ett direkt, sammanfattat svar.
 Figur 2: Samma fråga ställd till ChatGPT ger ett direkt svar.
Figur 2: Samma fråga ställd till ChatGPT ger ett direkt svar.
Problemen med Dagens Språkmodeller
Dessa språkmodeller är otroligt kunniga, men de har två grundläggande begränsningar:
- Begränsad kunskap: De kan i grunden bara svara på frågor med information som de har tränats på, vilket nästan uteslutande är offentligt tillgänglig data från internet. De vet ingenting om dina privata filer, företagsspecifika dokument eller interna rapporter.
- Hallucinationer: Ibland kan en språkmodell "hitta på" svar. Den presenterar felaktig information som om det vore fakta, ofta på ett mycket övertygande sätt.
Så hur kan vi använda kraften i dessa modeller för att få svar om vår egen, privata data, utan att riskera felaktigheter?
Lösningen: RAG – En Superkraft för AI
Här kommer Retrieval-Augmented Generation (RAG) in i bilden. Det är en teknik som ger språkmodeller superkrafter. RAG låter en modell svara på frågor om exklusiv och privat information, samtidigt som det drastiskt minskar risken för hallucinationer.
Men vad är då RAG, och hur fungerar det i praktiken?
Hur fungerar RAG? En Steg-för-Steg Guide
RAG-processen kan delas in i två huvudfaser: Förberedelse (där vi förbereder vår data) och Användning (där vi ställer en fråga och får ett svar).
Fas 1: Förberedelse (Indexering)
Det första steget handlar om att förbereda den information vi vill att AI:n ska kunna använda.
1. Extrahera Text: Säg att vi har hundratals företagsspecifika PDF-dokument. Först måste vi extrahera all text från dessa filer och omvandla den till ett rent textformat som en AI kan läsa, till exempel Markdown eller vanlig text.
2. Dela upp i Betydelsefulla Delar (Chunking): Att mata in tiotusentals sidor text direkt i en AI är ineffektivt. Istället delar vi upp den extraherade texten i mindre, meningsfulla delar, så kallade "chunks". Ofta delar man upp texten baserat på ett visst antal tokens (ord och delar av ord), till exempel 200 tokens per chunk. Man använder även en överlappning mellan varje chunk för att säkerställa att inga meningar eller viktiga sammanhang klipps av mitt itu. Under detta steg kan man även lägga till metadata – "data om data" – till varje chunk, exempelvis vilken PDF-fil och vilken sida den ursprungligen kom ifrån.
3. Skapa och Lagra Betydelse (Embeddings & Vector Database): Detta är det mest centrala steget. Varje text-chunk omvandlas till en embedding. En embedding är en matematisk representation av textens betydelse, lagrad som en lång lista med siffror (en vektor: [0.02, 0.91, ..., -0.55]). Vektorer som representerar text med liknande innebörd kommer att vara matematiskt "nära" varandra.
Dessa vektorer lagras sedan i en specialiserad vektordatabas, som är optimerad för att blixtsnabbt kunna söka efter och jämföra betydelsen hos tusentals eller miljontals sådana vektorer.
Fas 2: Användning (Hämtning & Generering)
När vår data är förberedd och lagrad i vektordatabasen kan vi börja ställa frågor.
4. Ställ en Fråga: När en användare ställer en fråga, till exempel "Vilka var våra största kunder under Q4?", genomgår frågan samma process som vår data: den omvandlas till en embedding-vektor som representerar frågans innebörd.
5. Hämta Relevant Information (Retrieval): Frågans vektor skickas till vektordatabasen, som utför en likhetssökning. Den letar reda på de text-chunks vars vektorer är mest lika frågans vektor. I praktiken betyder det att databasen hittar de delar av våra ursprungliga dokument som är mest relevanta för att besvara just den specifika frågan. Vi tar de X mest relevanta resultaten.
6. Generera ett Svar (Generation): I det sista steget tar vi de relevanta text-chunks som vi hämtade från databasen och skickar dem, tillsammans med den ursprungliga frågan, till en stor språkmodell som GPT-4. Språkmodellens uppgift är nu inte att svara fritt från sin allmänna kunskap, utan att agera som en smart sammanfattare. Den läser frågan och den medskickade kontexten och formulerar ett korrekt och välgrundat svar enbart baserat på informationen från våra dokument.
På detta sätt kan AI:n ge precisa svar om privat data och risken för hallucinationer minimeras, eftersom den har fått exakt den information den behöver för att svara korrekt.
Praktisk Demonstration
I videon nedan demonstreras en RAG-lösning i praktiken. Först visas hur systemet använder en kraftfull extern språkmodell (Google Gemini) för att svara på frågor om en PDF som innehåller riktlinjer för semesteransökan.
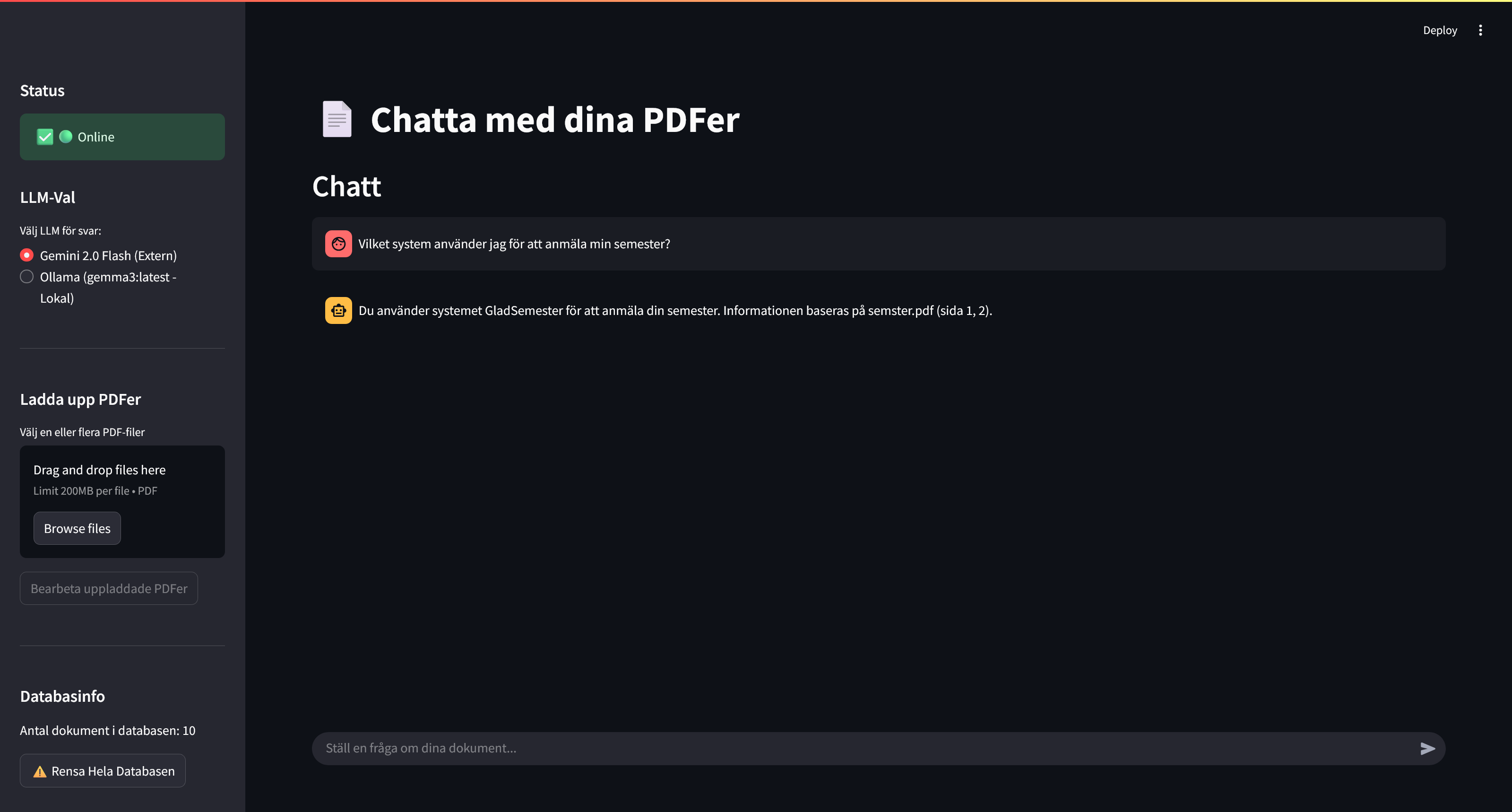 Figur 3: RAG-chatten använder här den externa språkmodellen Gemini 2.0 för att svara på frågor.
Figur 3: RAG-chatten använder här den externa språkmodellen Gemini 2.0 för att svara på frågor.
En av de stora styrkorna med RAG är dock att det även kan köras helt lokalt och offline. Detta visas också i videon, där internetuppkopplingen stängs av. Lösningen känner då av att den är offline och byter automatiskt till en lokal språkmodell (gemma3:4b via Ollama) som kan fortsätta svara korrekt på samma företagsspecifika frågor, helt utan internet.
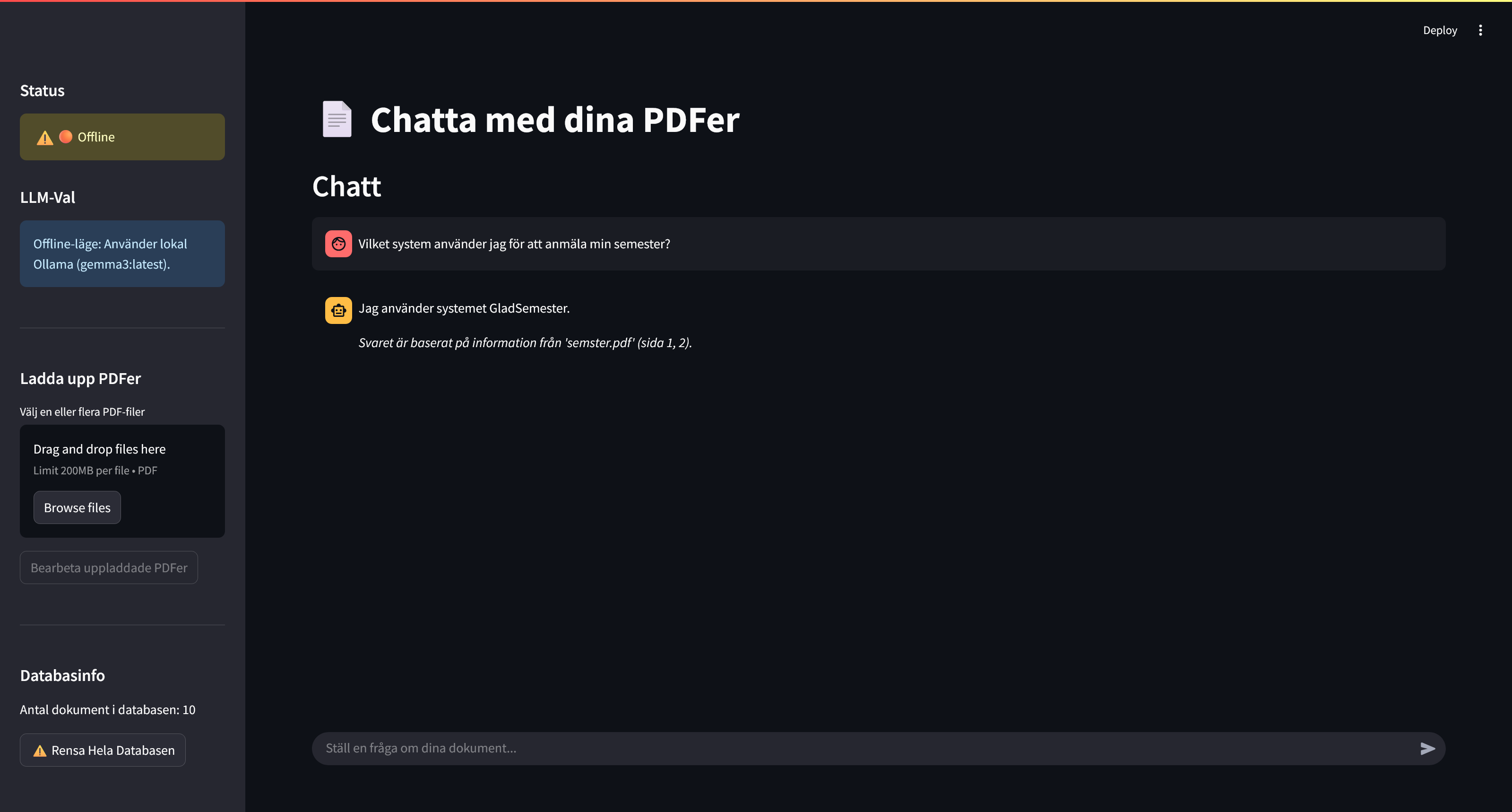 Figur 4: Här har lösningen växlat till den lokala modellen Gemma3:4b och fungerar helt offline.
Figur 4: Här har lösningen växlat till den lokala modellen Gemma3:4b och fungerar helt offline.
Se hela den tekniska genomgången och demonstrationen i videon här:
Om du vill förstå hur du kan få AI att arbeta med din data, är detta en video du inte vill missa.
Ytterligare fördjupning
För ytterligare fördjupning kring standard RAG eller andra, mer avancerade, typer av RAG-lösningar, kolla in vår sida om RAG-teknologier.
Resurser
- GitHub-repo (Chatt-applikation): streamlit-rag-pdf-chatter
- Embeddingmodell: intfloat/multilingual-e5-large-instruct
- Extern LLM (Google Gemini): Google AI Studio
- Applikationsramverk: Streamlit
- Lokal LLM (Ollama): gemma3:4b